
Cuando se utilizan equipos o redes digitales para transmitir o almacenar señales de voz, lo primero que hay que hacer es digitalizar la voz. Esto supone convertir la señal analógica de la voz (señal continua en tiempo y amplitud) en una señal digital o secuencia binaria de ceros y unos. A todo este proceso se le conoce como codificación de la voz.
La codificación de la voz ha evolucionado notoriamente desde las primeras ideas de Alec Reeves. Existen tres tipos generales de técnicas de codificación y decodificación de la voz o codecs:
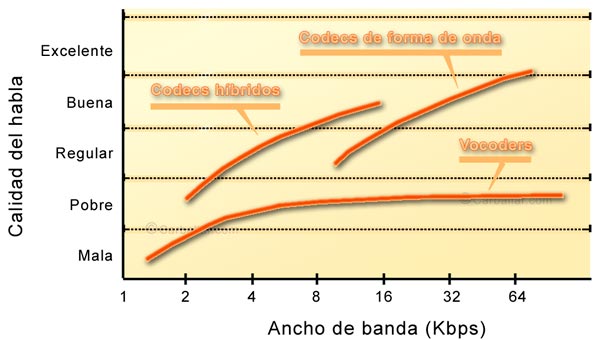
- De forma de onda. Básicamente muestrean la señal analógica y la codifican directamente. Transmiten los valores cuantificados al extremo distante, donde se reconstruye la señal original. Este sistema de codec es más bien simple y reproducen una buena calidad de sonido en destino. Su mayor inconveniente es que, comparado con otros sistemas, necesitan un gran ancho de banda para conseguir unos mismos niveles de calidad.
- Vocoder o de la señal origen. Con esta técnica se representa la señal sonora de acuerdo a un modelo matemático. Periódicamente identifica el modelo con el que se corresponde el sonido de la muestra y envía al destino los parámetros que lo identifican. En el destino se va reconstruyendo la forma de onda de acuerdo a los parámetros recibidos. Es de destacar que, en el caso del vocoder, no se transmite la información directa de la voz, sino los parámetros que la definen. Este sistema puede verse completado con un identificador de silencio para conseguir una mayor eficiencia. Con el sistema vocoder se puede reducir la necesidad de ancho de banda hasta los 2,4 Kbps. En este caso, el sonido no es de buena calidad (suena como metálico) pero es inteligible.
- Híbridos. El inconveniente del sistema vocoder es que no ofrece una alta calidad de sonido, ni aún aumentando considerablemente el ancho de banda. Para conseguir mejorar la calidad, se utilizan sistemas híbridos. Éstos ofrecen lo mejor de ambos sistemas anteriores, consiguiendo una muy buena calidad de sonido con un ancho de banda limitado.
Codec de forma de onda
Estos sistemas de codificación de la voz se basan en medir la amplitud de la señal de la voz en un instante determinado, indicar esa medida en forma binaria y transmitir la información al destino. Tomando estas medidas de forma reiterada y frecuente, se puede lograr regenerar la señal de la voz en el destino.
Los codec de forma de onda realizan la digitalización de la señal analógica de la voz en dos pasos:
- Muestreo
- Cuantificación
Cómo funciona el muestreo
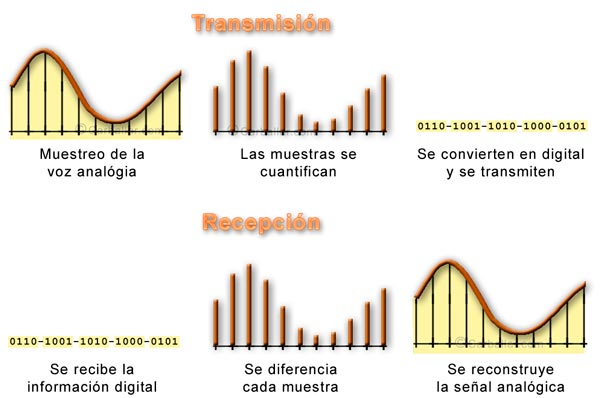
El muestreo consiste en tomar muestras periódicas del nivel de la señal analógica para representar posteriormente estos valores en forma binaria mediante las técnicas de cuantificación. La información binaria es transmitida al destino donde se le aplica el proceso inverso para conseguir una señal analógica similar a la original.
Para que la señal conseguida en destino reproduzca fielmente la señal original es necesario que el tiempo entre muestra y muestra sea tal que no pueda ocurrir nada impredecible entre ellas. En 1928, el sueco Harry Nyquist desarrolló la hipótesis de que la señal puede ser reconstruida siempre que las muestras se tomen a una frecuencia doble de la frecuencia máxima de la señal original. Esta hipótesis fue demostrada matemáticamente, y convertida en teorema, por el estadounidense Claude Shannon veinte años más tarde (1948). A pesar de ello, el teorema se conoce como teorema de Nyquist. No obstante, Shannon, que murió no hace mucho (año 2001), es considerado el padre de la teoría de la información (de donde viene la Sociedad de la Información).
Shannon es considerado el padre de la teoría de la información (de donde viene la Sociedad de la Información).
Volviendo al tema, si la máxima frecuencia de la señal analógica que se pretende retransmitir es 4.000 Hz, aplicando el teorema de Nyquist se deben tomar 8.000 muestras cada segundo, o lo que es lo mismo, una muestra cada 0,125 milisegundos.
En qué consiste la cuantificación
Una vez que sabemos cada cuánto tiempo tenemos que tomar muestras, la siguiente cuestión es cuántos bits son necesarios para representar este valor. Parece una pregunta simple, pero lo cierto es que cualquier valor digital sólo representa un conjunto de valores discretos. Por ejemplo, si el nivel de tensión máximo de la señal de la voz es 30 y utilizamos 2 bits para representarlo, sólo podremos transmitir 4 niveles de tensión (00, 01, 10 y 11). Estos niveles podrían corresponderse con los valores 0, 10, 20 y 30. Si en vez de 2 bits se utilizasen 3 ó 10, el número de niveles de tensión representados aumentaría, pero seguirían siendo limitados y, por lo tanto, seguiría existiendo la necesidad de realizar una aproximación.
A la asignación del valor binario correspondiente a cada valor real de la muestra se lo conoce como cuantificación. Como la cuantificación siempre se lleva a cabo por aproximación, esto quiere decir que existe un error (diferencia entre la señal original y la cuantificada) y, por tanto, la señal de destino será similar a la original, pero no idéntica. A este error se lo conoce como error o ruido de cuantificación.
Cuantos más bits se utilicen para representar cada muestra, mayor será la fidelidad de la señal en destino y, por tanto, menor el ruido de cuantificación. El inconveniente es que la velocidad de transmisión necesaria (ancho de banda) es directamente proporcional al número de bits de la muestra. En el caso de utilizarse 2 bits por muestra, la velocidad de transmisión necesaria sería de 16 Kbps (2 bits x 8.000 muestras al segundo).
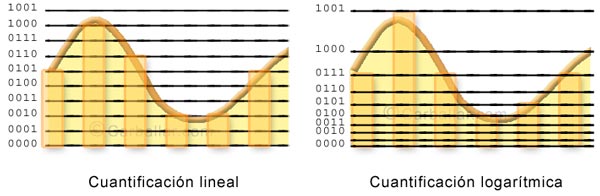
Una forma de mejorar el ruido de cuantificación sin aumentar el ancho de banda es dejar de aplicar una cuantificación uniforme para dedicarle más valores a los niveles bajos y menos a los niveles altos. Siguiendo con el ejemplo anterior, para representar los valores reales 8 y 28, tendríamos que utilizar los bits 01 y 11 (según la escala del ejemplo propuesto anteriormente). Estos dígitos identifican en realidad a los valores 10 y 30 (no 8 y 28). Aunque, de forma absoluta, la diferencia en ambos casos es 2, esta diferencia supone un 20% de error en el primer caso y un 7% de error en el segundo.
Para evitar esto se utiliza una cuantificación no uniforme (por ejemplo, logarítmica), aplicando una mayor granularidad a los niveles bajos que a los altos. En el ejemplo, a las cuatro combinaciones posibles se les aplicarían las amplitudes 0, 4, 12 y 30 (en vez de 0, 10, 20 y 30).
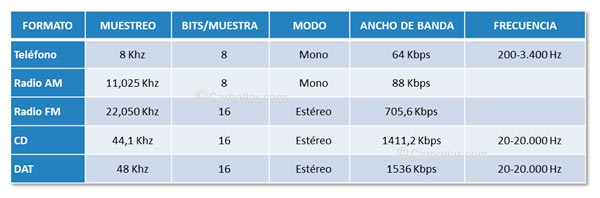
Desde 1972, las redes telefónicas han digitalizado la voz utilizando la recomendación G711 de la UIT-T. Este codec es de tipo forma de onda y utiliza 8 bits para cada muestra, lo que hace que la velocidad de transmisión de un canal telefónico sea 64 Kbps (8 x 8.000). Los equipos digitales de las redes telefónicas utilizan circuitos telefónicos de 64 Kbps siguiendo esta recomendación.
Qué es el Vocoder
Homer W. Dudley era un físico que trabajaba en los laboratorios Bell Telephone. En 1928 se le ocurrió el reto de reducir el ancho de banda necesario para transmitir la voz por las redes de telefonía. De esta forma se incrementaría la capacidad de transmisión de las redes de larga distancia sin tener que crear nueva infraestructura. Desarrolló una idea que consistía en analizar la señal de la voz para identificar los parámetros que la definen; de forma que transmitiendo estos parámetros se pueda resintetizar la voz en destino. A este proceso le dio el nombre de análisis y resíntesis del paso de banda de la voz.
Sus teorías las llevó a la práctica con un prototipo al que llamó Vocoder (Voice Coder o ‘Codificador de voz’). Con el tiempo, el vocoder evolucionó a un diseño más viable comercialmente y se le cambió el nombre por el de Voder. Este equipo se mostraría en la Feria Mundial de Nueva York de 1939.
El Voder nunca tuvo un éxito comercial, entre otras cosas, porque la idea de transformar las conversaciones telefónicas de la gente en murmullos robóticos no le pareció atractiva a los ejecutivos de las compañías telefónicas. No obstante, los militares descubrieron que este sistema facilitaba el cifrado de las comunicaciones, con lo que durante la segunda guerra mundial desarrollaron una versión digital (1942) que sería utilizada para establecer comunicaciones cifradas entre Roosevelt y Churchill.
Más información sobre la codificación de la voz y VoIP
Aquí se ha expuesto de forma resumida cómo funcionan la codificación de la voz. Con suerte, habré sido capaz de generar dudas y crear curiosidad sobre este tema. En este blog se dispone de muchos otros contenidos relacionados. Por favor, utilice el buscador de contenidos que tenemos en la cabecera de este blog.
Estos son algunos otros artículos que pueden ser de interés:
- Números binarios. Qué son y cómo funcionan
- Calidad de la voz en Internet o VOIP
- VoIP. La telefonía de Internet
REF: VOIP PG45