
Una red neuronal es un modelo de software especialmente pensado para programar soluciones de inteligencia artificial o IA (AI, artificial intelligence). Se le llama inteligencia artificial a los sistemas que realizan tareas similares a las que haría una inteligencia humana. Esto es, mantener una conversación, resolver un problema complejo o hacer un dibujo. Veamos qué son las redes neuronales y cómo funcionan.
Una red neuronal artificial es, por tanto, un software, un programa informático. A diferencia de los programas informáticos tradicionales, para que funcione un modelo IA, es necesario someterlo a un entrenamiento. Por tanto, red neuronal e inteligencia artificial están directamente relacionados con aprendizaje automático (machine learning) y aprendizaje profundo (deep learning). Estos dos términos son formas distintas de entrenar a la inteligencia artificial.
Entrenar una red neuronal consiste en ajustar cada uno de los pesos (parámetros) de las entradas de todas las neuronas que forman parte de la red neuronal, para que las respuestas ofrecidas se ajusten lo más posible a los datos que conocemos.
Los modelos de redes neuronales artificiales se llaman así porque son modelos inspirados en el funcionamiento del cerebro humano y son capaces de aprender de forma similar a como lo hace el cerebro humano.
Los modelos de redes neuronales artificiales se llaman así porque son modelos inspirados en el funcionamiento del cerebro humano. Esto es, son estructuras formadas por un conjunto de nodos conocidos como neuronas que están conectadas entre sí. Estas redes son capaces de aprender a través del entrenamiento, de forma similar a cómo el cerebro humano aprende y mejora sus capacidades para realizar tareas a través de la experiencia.

Google utiliza una red neuronal para clasificar las páginas más relevantes en función de cada búsqueda, Amazon utiliza una red neuronal para seleccionar los productos que recomienda en función del perfil del usuario o el buscador Bing ofrece su servicio de chat para que cualquier usuario pueda conversar con su inteligencia artificial (copilot). Más allá de esto, las empresas están incorporando soluciones de IA para relacionarse con sus clientes (chatbot), crear contenido o tomar decisiones estratégicas. La inteligencia artificial, las redes neuronales, están a nuestro alrededor y cada vez ocupan más espacio.
El objetivo de este artículo no es convertirse en experto en redes neuronales sino tener una idea de cómo funcionan estas soluciones y familiarizarse con la terminología de uno de los temas que más están de moda últimamente. Dicho de otra forma, la idea es simplemente situarnos en este contexto.
Qué es una Neurona
En el contexto de las redes neuronales, una neurona es simplemente una función. Para quien no lo recuerde, una función es algo que recibe uno o más valores de entrada, le aplica una determinada lógica y genera un resultado. Las funciones se suelen representar como y=f(x), donde x es el valor de entrada, f representa la lógica que se va a aplicar e y es el resultado.
Cada neurona, cada función, se utiliza para identificar un determinado detalle del valor de la entrada. Es como si cada neurona aportase una unidad de aprendizaje al conjunto. El valor de esta unidad se guarda para poderlo relacionar con el resultado final.
Por tanto, una neurona es una unidad básica del procesamiento de la información que se utiliza para modelar el funcionamiento de la inteligencia artificial. Cada una recibe una o más entradas, le aplica una lógica (una operación o un cálculo) y produce una salida. Dicho de otra forma, se puede decir que cada neurona es una unidad de aprendizaje.
Las neuronas están interconectadas entre si. Cada neurona recibe entradas de otras neuronas o de fuentes externas, y producen su salida que, a su vez, es enviada a otras neuronas o a la salida final de la red. En una red neuronal artificial, las neuronas se organizan en capas, y la información fluye de la capa de entrada a través de una o más capas intermedias (conocidas como capas ocultas) hasta la capa de salida. Cada capa está compuesta por varias neuronas, y la interconexión entre las neuronas permite que la red aprenda a reconocer patrones y realizar tareas específicas, como clasificar imágenes o predecir valores numéricos.
Qué es el aprendizaje automático o machine learning
El aprendizaje automático o machine learning forma parte integral del modelo de inteligencia artificial. Por tanto, se trata de un modelo de programación con el objetivo de ofrecer la solución a un problema, pero de una forma distinta a como resuelven los problemas la forma clásica de programación.
En la programación clásica, la persona que hace el programa necesita comprender el problema que trata de resolver y tiene que definir absolutamente todas las reglas que llevan a la solución. En este caso, el programador crea un algoritmo cerrado en el que están definidos los valores que espera de entrada, les aplica una lógica y genera unos valores de salida. Por ejemplo, un programa puede esperar que se le introduzcan dos números como entrada, con un formato concreto; le aplica la lógica de multiplicarlos y ofrece la salida (resultado de la multiplicación). Tanto la naturaleza de los datos de entrada, como la lógica a aplicar se conocen de antemano.
En el aprendizaje automático no se programa una lógica que resuelva un problema concreto. Lo que se hace es desarrollar algoritmos y modelos estadísticos que permitan a las máquinas aprender de forma autónoma sin ser programadas explícitamente para una tarea específica. Por tanto, para que el modelo pueda saber lo que tiene que hacer es necesario que sean entrenados previamente. Por ejemplo, se les ofrece muchas parejas de valores y los resultados de sus multiplicaciones. Después del entrenamiento, el software determina la lógica que relaciona las entradas con las salidas y está lista para funcionar. Si se le introducen dos números, nos dará su multiplicación.

Como podemos ver, el modelo, el software, de aprendizaje automático es genérico. Lo que hace que este modelo pueda resolver nuestro problema es su entrenamiento. Dicho de otra forma, en lugar de escribir un conjunto de instrucciones detalladas para que una máquina realice una tarea determinada, los algoritmos de aprendizaje automático se diseñan para aprender de manera autónoma patrones y relaciones entre los datos a partir de ejemplos previos. Una vez entrenado, utiliza estos patrones para hacer predicciones o tomar decisiones que lleven a la solución.
A medida que se recopilan y procesan más datos, los modelos de aprendizaje automático se vuelven más precisos y sofisticados. En términos generales se puede decir que el aprendizaje automático es aprender con ejemplos.
Existen soluciones de aprendizaje automático de distinta naturaleza, dependiendo del problema a resolver para el que estén diseñados. A diferencia del deep learning, que veremos más adelante, las técnicas de machine learning suelen estar basadas en modelos estadísticos. No obstante, también existen modelos de machine learning basados en redes neuronales.
Qué es una red neuronal
Una red neuronal es una forma práctica de crear modelos de aprendizaje automático. Si una neurona es una función, una red neuronal es un conjunto de funciones. Se trata de miles de funciones interconectadas y diseñadas para que, una vez que se entrenan, quede determinada la relevancia de cada una de ellas para llegar a la solución del problema.
Las redes neuronales no son válidas para resolver cualquier tipo de problemas. Tienen que estar específicamente diseñadas para el tipo de problemas al que se van a enfrentar. Por ejemplo, no es lo mismo ChatGPT, que toma un texto de entrada y produce un texto de salida, que Dall-e que genera imágenes a partir del texto de entrada.
Para diseñar una red neuronal hay que resolver preguntas como:
- ¿Cómo se gestionan las entradas y salidas?. Por ejemplo, si la entrada es un texto, ¿utilizo solo letras? ¿números? ¿vectores?.
- ¿Qué funciones utilizamos en cada neurona?. Son ¿lineales? ¿exponenciales?
- ¿Cuál es la arquitectura de la red?. Esto es, ¿la salida de qué función es la entrada de qué otra?
- etc.
Una vez respondidas todas las preguntas y creada la red, hay que proporcionarle una gran cantidad de entradas con sus salidas correctas. Con esto, el sistema ajusta la relevancia de cada función en la resolución del problema. Esto es, ajusta sus parámetros. La esperanza es que cuando se le muestre una nueva entrada que nunca ha visto, pueda dar con la salida correcta.
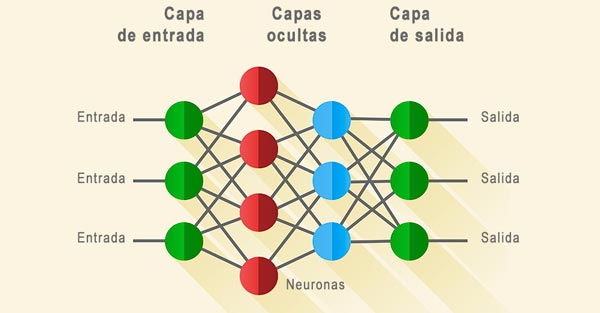
Las neuronas de las redes neuronales se organizan en capas. Existen tres niveles de capas:
- Capa de entrada. Es la capa que contiene las neuronas que reciben los datos de entrada. Representan el número de características que la red neuronal va a utilizar para hacer sus predicciones. Se necesita una neurona de entrada por cada característica.
- Capas ocultas. Son las capas intermedias entre las capas de entrada y de salida. Las capas ocultas buscan cualquier característica oculta en los datos. Las redes neuronales tradicionales (de aprendizaje automático) tienen solo 2 o 3 capas ocultas, pero las redes neuronales de aprendizaje profundo pueden tener hasta 150 capas ocultas y cada capa puede estar formada por hasta 100 neuronas. La mayoría de las neuronas de las redes neuronales se encuentran en las capas ocultas. Por otro lado, son el corazón de la manipulación de los datos para obtener la salida deseada. Los datos son manipulados por muchos pesos y sesgos a su paso por las capas ocultas.
- Capa de salida. Es la capa que contiene las neuronas que muestran los datos de salida. Se utiliza una neurona por cada dato de salida.
Las redes neuronales artificiales pueden utilizar millones de neuronas (funciones) y parámetros. Se trata, por tanto, de un modelo complejo que necesita ser diseñado con mucho cuidado. Hay un arduo trabajo de investigación detrás. Si le interesa tener una mejor idea de lo que esto significa, puede hacer uso de esta mesa de juego Neural Network Playground creado por Daniel Smilkov y Shan Carter.
Ejemplo de aprendizaje automático
Para ilustrar el aprendizaje automático con un ejemplo, digamos que tratamos de entender la relación entre el precio de un producto y el número de unidades vendidas. Como estamos utilizando una red neuronal con aprendizaje automático, la manera de averiguarlo es proporcionando muchos ejemplos.
Por tanto, experimentamos con distintos precios (x) y anotamos las ventas realizadas (y) en distintos entornos y momentos. Se supone que hay una relación entre ellos: y=f(x). Le digo a la máquina, al programa, que entre ellos debe darse una relación lineal (una línea recta) y la máquina determina el tipo de línea que debe establecer.
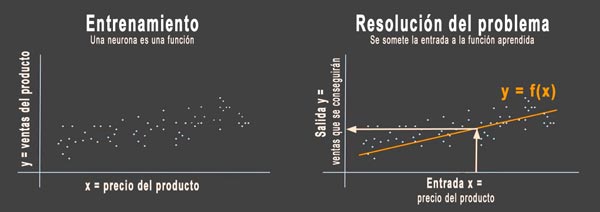
La próxima vez que necesite fijar un precio, solo tengo que preocuparme por cuántas unidades quiero vender. La máquina aplicará la relación encontrada (f) y nos dará el precio.
Este ejemplo es muy simple y, posiblemente, bastará con un par de neuronas para resolverlo, pero nos da una idea de cómo es el proceso.
Aprendizaje automático vs aprendizaje profundo
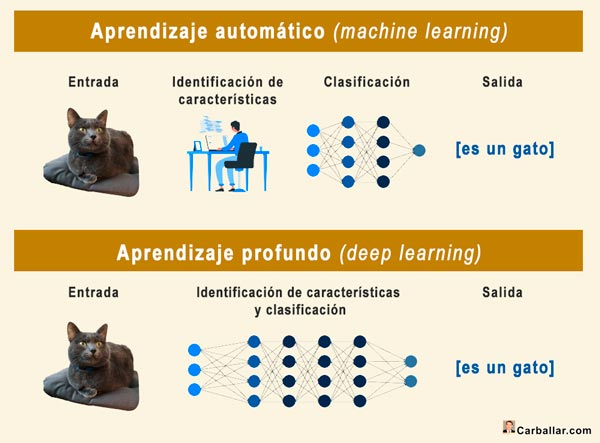
El aprendizaje profundo o deep learning es un tipo de aprendizaje automático. Básicamente, mientras que en el aprendizaje automático es necesaria la intervención humana en parte del proceso de entrenamiento, en el aprendizaje profundo el entrenamiento se realiza de forma completamente automatizada.
Para construir un modelo de aprendizaje automático es necesario que previamente se identifiquen las características (funciones) importantes de las entradas que nos llevan a determinar la solución. A continuación, se construye el modelo. En el caso del aprendizaje profundo, las características relevantes de las entradas se identifican automáticamente. Por otro lado, mientras que las redes de aprendizaje automático reciben los datos de entrada de forma estructurada, las de aprendizaje profundo reciben los datos sin procesar.
Las redes de aprendizaje profundo son mucho más complejas que las de aprendizaje automático. Esto quiere decir que requieren un número mucho mayor de capas, lo que conlleva disponer de procesadores mucho más potentes. Por otro lado, las redes de aprendizaje profundo mejoran considerablemente la calidad de los resultados con la cantidad de datos de entrenamiento.
Tipos de redes neuronales
Como hemos visto, las redes neuronales son modelos de software que se pueden diseñar con distintos propósitos. La experiencia ha demostrado que unas configuraciones son muy aptas para unos propósitos y muy torpes para otros. Esto nos lleva a que existen distintos tipos de redes neuronales. Los principales son los siguientes:
- Perceptrón. Es la red neuronal más antigua y simple. Fue desarrollada por Frank Rosenblatt en 1958. Aunque tiene una sola neurona, el perceptrón sentó las bases de los fundamentos de las redes neuronales. Tiene n entradas y una sola salida. Se utiliza fundamentalmente para comprender el funcionamiento de las redes neuronales.
- Perceptrón multicapa o MLP (Multi Layer Perceptron). Sigue siendo un perceptrón, pero utiliza tres capas (entrada, oculta y salida), lo que le da la estructura de una red neuronal completa (aunque sigue siendo simple).
- Red neuronal convolucional o CNN (Convolutional Neural Network). La particularidad de este tipo de redes es que cada neurona no se une con todas y cada una de las neuronas de la capa siguientes, sino solo con un subgrupo de ellas (se especializa). Con este modelo se reduce el número de neuronas necesarias, así como la complejidad computacional necesaria para su ejecución. Se utilizan generalmente para imágenes y vídeo, así como para modelos PLN o de procesamiento del lenguaje natural.
- Red neuronal recurrente o RNN (Recurrent Neural Network). Estas redes no tienen una estructura de capas, sino que permiten conexiones arbitrarias entre las distintas neuronas. Pueden crear ciclos, con lo que se consigue crear la temporalidad, permitiendo que la red tenga memoria. Los datos introducidos en el momento t en la entrada, son transformados y van circulando por la red incluso en los instantes de tiempo siguientes t + 1, t + 2, etc. Este modelo es apropiado para datos temporales, datos que dependen de instancias pasadas para predecir el futuro. Por ejemplo, predecir el comportamiento del mercado de valores.
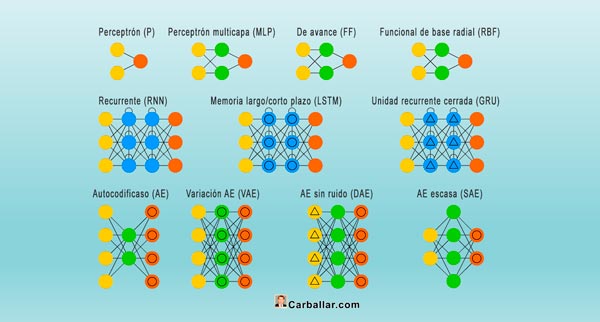
- Red neuronal de avance o FF (Feed forward Principal). Se encuentran entre los tipos más básicos de redes neuronales. La información pasa a través de varios nodos de entrada en una dirección hasta que llega al nodo de salida. La red puede incluir o no capas de nodos ocultos. Se suele utilizar para el reconocimiento de patrones y para la visión por ordenador (obtener información relevante de fotos y vídeos).
- Red funcional de base radial o RBF (Radial Basis Functional). Las redes de base radial calculan la salida de la neurona en función de la distancia a un punto denominado centro. La salida es una combinación lineal de las funciones de activación radiales utilizadas por las neuronas individuales. Las redes de base radial tienen la ventaja de que no presentan mínimos locales donde la retropropagación pueda quedarse bloqueada.
Esto es una pequeña muestra de los tipos existentes y para qué son aptos cada uno de ellos. En realidad, existe una gran variedad y cada día surgen modelos nuevos, cada vez más complejos y efectivos.
Qué son las funciones de activación
Como se ha visto, las redes neuronales están formadas por neuronas. Cada neurona es un elemento básico de procesamiento que recibe una o más entradas y produce una salida. La salida de la neurona se calcula mediante una función matemática que toma en cuenta las entradas recibidas y los pesos asociados a cada entrada.
El proceso de cálculo en una neurona se realiza en dos etapas:
- Se realiza una combinación lineal de las entradas y los pesos asociados a cada entrada. Esto significa que cada entrada se multiplica por su peso correspondiente y los resultados se suman para obtener una única cantidad.
- A la cantidad anterior se le aplica una función matemática conocida como función de activación. Esta función suele ser del tipo no lineal, lo que permite que la red sea capaz de modelar funciones complejas.

El resultado de la función de activación es la salida de la neurona, que se utiliza como entrada para la siguiente capa de la red neuronal. Existen diferentes tipos de funciones de activación como, por ejemplo: la función sigmoide, la función ReLU o la función tangente hiperbólica, entre otras.
Qué son los algoritmos de las redes neuronales
Por otro lado, para el cálculo de los pesos y umbrales asociados a cada entrada se utilizan algoritmos matemáticos. Estos algoritmos son un conjunto de procedimientos matemáticos y estadísticos que se utilizan para entrenar y ajustar los parámetros de la red neuronal. El objetivo es que la red pueda aprender de forma automática a partir de los datos de entrenamiento.
Existen diferentes tipos de algoritmos de redes neuronales, como el algoritmo de retropropagación (backpropagation), descenso del gradiente estocástico (Stochastic Gradient Descent, SGD), propagación hacia adelante (feedforward), método de Newton, gradiente conjugado, entre otros.
Como podemos suponer, cada función de activación y cada uno de estos algoritmos tiene sus propias características y se utiliza en función de la tarea específica que se desea resolver y de las propiedades de los datos de entrenamiento.

Red neuronal de lenguaje natural
Una red neuronal artificial para lenguaje natural es un tipo de red neuronal diseñada específicamente para trabajar con datos de lenguaje natural, como texto o voz. Estas redes neuronales pueden ser utilizadas para una variedad de tareas de procesamiento del lenguaje natural (conocidos como PLN o NLP, natural language processing), lo que incluye la clasificación de textos, generación de textos, traducción automática o el reconocimiento de voz.
La forma en que funciona una red neuronal de este tipo depende de varios factores. En general, se diseñan para procesar datos de lenguaje natural en forma de secuencias de palabras o caracteres. Para ello, lo primero que hacen es convertir cada palabra del texto en su representación numérica. Cada palabra del diccionario se representa como un número, un vector.
Entre las arquitecturas de red neuronal más utilizadas para el procesamiento del lenguaje natural está la red neuronal recurrente (RNN) o la red neuronal convolucional (CNN). No obstante, recientemente se está utilizando un tipo de red más moderna conocida como red neuronal transformer.
La red transformer utiliza múltiples capas (llamadas capas de atención) para procesar la entrada y producir una salida. En lugar de usar una red recurrente para procesar la entrada secuencialmente, la atención permite que la red pueda identificar y centrarse en partes específicas de la entrada (palabras específicas), independientemente de su posición relativa en la secuencia. La red recibe una oración de entrada y la convierte en dos secuencias: una secuencia de vectores de palabras (número asignado a cada palabra) y una secuencia de codificaciones posicionales. Ambos vectores son escritos usando representaciones numéricas del texto para que la red neuronal pueda procesarlas.
Las redes neuronales de tipo transformer resultan ser muy efectivas en tareas como la traducción automática o la generación de textos. Por ejemplo, el famoso servicio ChatGPT de OpenAI o la IA de Bing utilizan una red neuronal de este tipo.
En general, una red neuronal para lenguaje natural se entrena utilizando datos etiquetados y un algoritmo de aprendizaje supervisado. La red ajusta los pesos y los sesgos de sus neuronas para minimizar el error entre sus predicciones y las etiquetas correctas de los datos de entrenamiento. Una vez entrenada, la red se puede utilizar para hacer predicciones sobre nuevos datos de entrada.
Para hacernos una idea, el famoso ChatGPT de OpenAI se basa en su modelo de red neuronal conocido como GPT. La primera versión de GPT (GPT-1, de 2018) se entrenó en un conjunto de datos de texto de 40 GB (textos de internet, incluyendo libros, artículos de noticias, sitios web, entre otros muchos documentos) y utilizaron 117 millones de parámetros. La segunda versión (GPT-2) es de 2019 y utilizaron 1.500 millones de parámetros. GPT-3 es de 2020 y utilizaron 175 mil millones de parámetros y GPT-4 (marzo de 2023) utilizaron 100 millones de millones de parámetros (1014, 100 billones europeos, no americanos). El hecho es que cada una de estas nuevas versiones han mejorado considerablemente su capacidad para ofrecer respuestas coherentes en una dinámica de conversación natural.
Más información sobre redes neuronales
La inteligencia artificial es un campo que está recibiendo una gran atención mediática últimamente. Cada día aparece una nueva noticia indicando las maravillas que se están consiguiendo con estos desarrollos. Lo cierto es que esta tecnología no ha hecho más que empezar, por lo que nos esperan todavía muchas sorpresas.
Si está interesado en adquirir un conocimiento más detallado sobre las redes neuronales, existen multitud de referencias. Por ejemplo, el blog de Christopher Olah aborda estos temas con profundidad técnica. También se puede profundizar en el aprendizaje automático en sitios como Scikit-learn. Alternativamente, se puede acceder a ChatGPT o al chat de Bing y preguntarle a estas inteligencias artificiales cualquier duda o aclaración que se tenga sobre el tema.
Las redes neuronales son temas apasionantes que da para muchas historias. Si busca inspiración o simplemente le interesan estos temas, en este blog se dispone de muchos otros contenidos relacionados. Por favor, utilice el buscador de contenidos que tenemos en la cabecera.
Por otro lado, estos son algunos otros artículos que pueden ser de interés: