
Internet es una inmensa base de datos donde podemos encontrar todo tipo de información. El problema es que internet es tan grande, que encontrar exactamente la información que se necesita es todo un reto. La herramienta fundamental para buscar información en internet se conoce con el nombre de buscador o motor de búsqueda (search engine). Un buscador es un servicio en el que introducimos cualquier palabra o frase y nos responde con un listado de sitios de internet relacionados con dicho texto. La historia de los buscadores de internet va ligada a la evolución tecnológica de la red.
En los comienzos de internet no existían las páginas web, por lo que el contenido se compartía en formato de archivos. Los primeros buscadores eran simples listados de archivos que se podían re visar manualmente. La aparición del servicio Web a principio de los años 1990 supuso que se pudiera compartir información de una forma más simple. Los contenidos de internet crecieron exponencialmente e hizo necesario que existiera un intermediario que nos facilitara la labor de búsqueda. Ese fue el comienzo de los buscadores tal y como los conocemos hoy.
La tecnología y especialmente la inteligencia artificial está haciendo que los buscadores evolucionen para convertirse en asistentes cada vez más personales. No obstante, el equilibrio entre el derecho a la privacidad y los intereses publicitario está haciendo que esta evolución sea un poco incierta. En cualquier caso, centrémonos en el pasado.
Internet es una inmensa base de datos donde podemos encontrar todo tipo de información. El problema es que internet es tan grande, que encontrar exactamente la información que se necesita es todo un reto. La herramienta fundamental para buscar información en internet se conoce con el nombre de buscador o motor de búsqueda (search engine). Un buscador es un servicio en el que introducimos cualquier palabra o frase y nos responde con un listado de sitios de internet relacionados con dicho texto. La historia de los buscadores de internet va ligada a la evolución tecnológica de la red.
En los comienzos de internet no existían las páginas web, por lo que el contenido se compartía en formato de archivos. Los primeros buscadores eran simples listados de archivos que se podían re visar manualmente. La aparición del servicio Web a principio de los años 1990 supuso que se pudiera compartir información de una forma más simple. Los contenidos de internet crecieron exponencialmente e hizo necesario que existiera un intermediario que nos facilitara la labor de búsqueda. Ese fue el comienzo de los buscadores tal y como los conocemos hoy.
La tecnología y especialmente la inteligencia artificial está haciendo que los buscadores evolucionen para convertirse en asistentes cada vez más personales. No obstante, el equilibrio entre el derecho a la privacidad y los intereses publicitario está haciendo que esta evolución sea un poco incierta. En cualquier caso, centrémonos en el pasado.
Prehistoria. Antes del servicio web
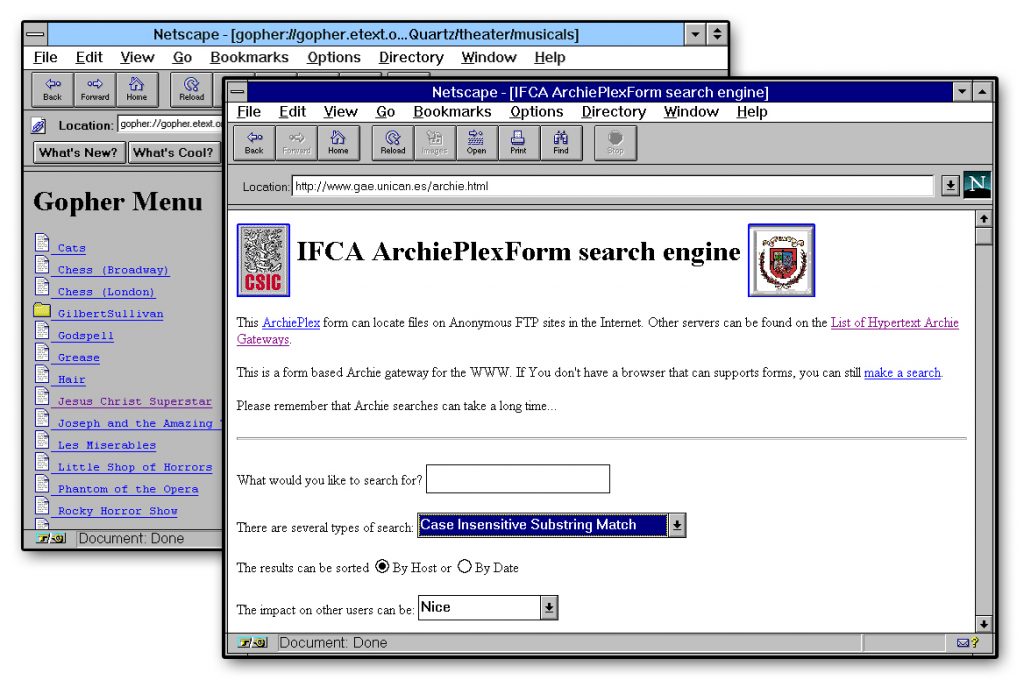
En 1990 no existía el World Wide Web, la información se guardaba y compartía en internet por medio de archivos. El sistema que permitía compartir estos archivos era un software de transferencia de archivos conocido como FTP (File Transfer Protocol). Con el programa FTP podías ver el listado de los archivos de que disponía un servidor y bajar (o subir) los que te interesasen. En este entorno, Alan Emtage, Bill Heelan y J. Peter Deutsch, estudiantes de la Universidad McGill de Montreal, crearon en 1990 un buscador conocido como Archie. Archie creó una base de datos de todos los archivos disponibles en la red accediendo a los servidores FTP públicos y bajándose el listado de archivos de que disponían. Por aquel entonces, la información disponible era tan limitada que las búsquedas se podían hacer manualmente en estos listados.
En 1991 surge una nueva forma de presentar la información en internet conocida como Gopher. Sus desarrolladores fueron Paul Lindner y Mark P. McCahill de la Universidad de Minnesota. Gopher permitía mostrar la información mediante menús jerarquizados. Se trataba de información de textos, sin imágenes ni hiperenlaces, pero mucho más amigables que los listados de archivos existentes hasta entonces. Pues bien, en diciembre de 1992 surge en la Universidad de Nevada un buscador de documentos Gopher. Hablamos de Veronica. Poco después, marzo de 1993, surge un competidor conocido como Jughead.
Los primeros motores de búsqueda
El World Wide Web fue creado en 1991 por Tim Berners-Lee. En 1993 ya existía un gran número de servidores webs y sus usuarios simplemente creaban y mantenían manualmente sus listados de servidores preferidos. En septiembre de ese año, Oscar Nierstrasz, profesor de la Universidad de Ginebra, escribió una aplicación que recogía periódicamente la información de estos listados manuales y la presentaba en lo que pretendía ser un índice de los recursos de internet: el W3Catalog. Aunque primitivo, este fue quizás el primer buscador de la web. Llegó a ser muy popular, pero murió joven, al sustituirse el trabajo manual por los motores de búsqueda.
En junio de 1993 apareció el primer motor de búsqueda de páginas webs. Su creador fue Matthew Gray y le puso el nombre de Wanderer. Wanderer utilizaba un software que rastreaba automáticamente toda la red e iba clasificando la información que encontraba. Esto es lo que se conoce como robot de búsqueda. El robot de búsqueda que utilizaba Wanderer creó una cierta polémica al ser acusado de degradar la calidad de la red. Como respuesta, Martin Koster creó Aliweb, un buscador que no utilizaba un robot, sino que se basaba en la información que daban de alta los propios administradores de los servicios web. Aliweb apareció en octubre de 1993.
A pesar de lo anterior, la idea de utilizar robots, o spiders, para buscar la información de las webs era fuertemente atractiva. En diciembre de 1993 aparecieron tres buscadores que utilizaban robots: JumpStation, WWW Worm y RBSE (Repository-Based Software Engineering). JumpStation fue el primero en ofrecer un formulario web que facilitara la búsqueda de información a sus usuarios. Esto hizo que JumpStation se convirtiera en el primer servicio web de búsqueda de información en internet que disponía de los tres elementos básicos de una buscador moderno: robot de búsqueda, base de datos indexada e interfaz web de usuario. Por su parte, RBSE fue el primer buscador en implementar un sistema de valoración de la relevancia de los resultados de la búsqueda. Hasta entonces, el orden de presentación de las respuestas era casual. El autor de RBSE es David Eichmann.
El problema de los buscadores de aquella fecha es que ninguno tenía la inteligencia para analizar la información que estaba referenciando. En enero de 1994 surgió Galaxy con la idea de mejorar esta deficiencia. Galaxy se convirtió en el primer buscador en utilizar directorios temáticos con un árbol de categorías jerarquizadas.
Yahoo. El primer buscador de éxito
El primer buscador de páginas web que llegó a ser popular fue Yahoo. En abril de 1994, dos estudiantes de doctorado de la Universidad de Stanford, David Filo y Jerry Yang, crearon una colección de sus páginas favoritas de internet. En un principio la compartieron con sus amigos y se dedicaron a aumentar el número de referencias. Esto les forzó a buscar una mejor forma de organizar los datos. Crearon una estructura de categorías donde las referencias eran introducidas manualmente. El resultado fue todo un éxito: Yahoo Directory. Un año más tarde incluirían la función de buscador facilitada por Open Text.
En cualquier caso, la función de búsqueda operaba sobre su directorio, no sobre el texto completo de las páginas web. Por cierto, en inglés, se le llama yahoo a las personas rudas y poco inteligentes, el típico musculoso sin cerebro. Ellos afirman que Yahoo se corresponde con el acrónimo Yet Another Hierarchical Officious Oracle (Otro Oficioso Oráculo Jerarquizado). La clave del éxito de Yahoo fue el boca a boca. En menos de un año recibía más de dos millones de visitas diarias.
Los buscadores de contenido
Los robots de búsqueda fueron mejorando. Pero hasta entonces los robots realizaban las búsquedas exclusivamente sobre el URL o los textos de descripción de las páginas webs. Estamos en 1994, los estudiantes del Departamento de Ingeniería e Informática de la Universidad de Washington organizaron un seminario sobre internet y World Wide Web. Brian Pinkerton presentó su proyecto Webcrawler. La novedad de Webcrawler era que se trataba del primer buscador que realizaba búsquedas dentro del texto completo de las páginas webs. Los amigos de Brian le animaron a crear una interfaz web y ponerla en internet. El 20 de abril de 1994 nacía Webcrawler y rápidamente se convirtió en uno de los buscadores favoritos de los usuarios. Excite compraría Webcrawler en 1997.
El siguiente hito en la historia de los buscadores fue Lycos. Creado por Michael Mauldin en la Universidad de Carnegie Mellon, vio la luz en julio de 1994. Su mérito: tener el mayor catálogo de referencias de la época. En octubre de 1994 fue clasificado como el buscador que ofrecía el mayor número de respuestas. En 1996 tenía clasificados más de 60 millones de documentos.
En febrero de 1995 apareció Infoseek. Este buscador utilizaba una tecnología híbrida entre Yahoo y Lycos, pero tuvo el acierto de crear una interfaz amigable con muchos servicios adicionales (noticias, directorios, etc.).
Metabuscadores y lenguaje natural
En 1995 parecía bastante complicado innovar con los buscadores. No obstante, a Eric Selburg de la Universidad de Washington se le ocurrió crear un metabuscador. Un buscador que realizase la misma consulta en distintos buscadores (Lycos, Altavista, Yahoo, Excite y Webcrawler) y mostrase los resultados en una misma página. El nombre de este buscador fue Metacrawler. En poco tiempo se convirtió en uno de los buscadores más utilizados.
En diciembre de 1995 apareció Altavista. Este buscador, creado por DEC (Digital Equipment Corporation), no sólo tenía la novedad de ser extremadamente rápido en presentar sus resultados (DEC dimensionó generosamente el hardware utilizado), sino que fue el primero en admitir consultas con lenguaje natural. Por ejemplo, se le podía consultar ¿Qué tiempo hace en Mar del Plata?, sin que por ello diese miles de respuestas que contuviesen la palabra tiempo o plata. Además fue el primero en introducir el uso de los operadores lógicos (y, o, no, etc.).
En 1996, Eric Brewer, un profesor de Informática de la Universidad de California en Berkeley, y Paul Gauthier, un estudiante de doctorado en Informática, tuvieron la idea de comercializar el fruto de sus investigaciones: una tecnología de búsqueda de alto rendimiento. El 20 de mayo de 1996 se creaba Inktomi Corporation y nacía un nuevo buscador: HotBot.
La aportación de HotBot era su gran capacidad de indexación. Presumía de poder reindexar diariamente toda su base de datos. Esto significa que los resultados ofrecidos estaban todos actualizados. Éste era precisamente el problema mayor de los otros buscadores, que podían ofrecer enlaces anticuados ya inexistentes. HotBot fue también de los primeros buscadores en utilizar la tecnología Cookie para conocer las preferencias de búsqueda de sus usuarios.
El primer buscador hispano
En 1996, la mayoría de la información que podía ser encontrada en los buscadores estaba en inglés. Cualquiera que no se manejase en inglés encontraba dificultades para buscar la información de su interés. Eso fue lo que pensó Pep Valles al crear el primer buscador hispano: Olé. En un principio, Olé funcionó como directorio temático y, en poco tiempo, se convirtió en el buscador preferido de los hispanohablantes.
En marzo de 1999 Telefónica compró Olé para crear un gran buscador hispano conocido como Terra. En mayo de 2000 Terra compraría Lycos para formar uno de los principales buscadores internacionales. Lo cierto es que Terra Lycos se vería pocos años después superada tecnológicamente por sus competidores y tuvo que cambiar su estrategia de negocio. No obstante, sus intentos de supervivencia no servirían de mucho. El gigante tecnológico que llegó a ser Terra finalmente se acabó desmoronando.
La aparición de Google
En 1998 aparecía en el mercado un nuevo líder entre los buscadores. Se trata de Google. A finales de 1995, Sergey Brin (23 años) y Larry Page (24 años) empiezan a trabajar en el proyecto de Biblioteca Digital de la Universidad de Stanford. Su primera tarea fue crear un algoritmo para la búsqueda de datos. A este algoritmo patentado le dan el nombre de pagerank (clasificado de páginas). A principios de 1996 crean un buscador, llamado BackRub, cuya mayor habilidad es analizar los enlaces que apuntan a una determinada dirección (back links). Este nuevo sistema da sus resultados y, después de un tiempo de pruebas, BackRub se transforma en Google. El nombre de Google viene de su parecido con la palabra googol, nombre que se le da a la cifra formada por un uno y cien ceros.
El algoritmo pagerank de Google permite clasificar la relevancia de las páginas web para cada término buscado. Como lo definió su creador: ‘…Pagerank es una forma de poner orden en la web…’. Los buscadores anteriores clasificaban la relevancia en función del número de veces que aparecían los términos buscados en la página o cómo estaban relacionados estos términos dentro de la página. Pagerank, sin embargo, asume que la relevancia de una página es mayor cuantas más veces sea enlazada por otras, sobre todo, si el pagerank de esas otras páginas es alto. Esto es, supone que las páginas web enlazadas desde muchas páginas importantes probablemente sean importantes en sí mismas y aporten resultados más relevantes para el usuario. A lo largo de los años, Google ha agregado mucho otros criterios para determinar la clasificación de los resultados. Se dice que tiene más de 200 indicadores secretos diferentes.
La presentación de resultados de búsqueda más precisos, así como la utilización de un interfaz minimalista, pronto catapultaron a Google al liderato. Adicionalmente, Google no solo indexa y almacena en caché una copia de todas las páginas web, sino que también guarda copias de otros tipos de archivos (incluyendo PDF, documentos Word, hojas de cálculo Excel, archivos de texto sin formato, etc.).
Microsoft Bing
En 1998 aparece el buscador de Microsoft: MSN search. En los primeros años Microsoft no disponía de su propio motor de búsqueda, así que utilizaba los resultados que le ofrecía Inktomi. En cualquier caso, su éxito fue muy limitado. En el nuevo milenio se producen múltiples movimientos empresariales de compra y venta de buscadores. En 2002 Yahoo adquiere Inktomi y Overture (el dueño de Altavista). Microsoft empieza a utilizar su propio motor de búsqueda en 2004 (llamado msnbot). Ese mismo año nace Hakia, un nuevo buscador que tiene la particularidad de realizar búsquedas semánticas. Esto quiere decir que basa sus búsquedas en el significado de las palabras, más que en las palabras en sí. En julio de 2007 apareció el buscador Wikia Search, liderado por el fundador de Wikipedia, Jimmy Walles.
En 2009 Microsoft introduce mejoras en su buscador y le cambia el nombre por Bing. Entre las mejoras incluye una lista de sugerencias de búsqueda en tiempo real y una lista de búsquedas relacionadas basada en tecnología semántica desarrollada por Powerset (empresa que había comprado en 2008). En ese mismo año, Microsoft llega a un acuerdo con Yahoo para que este último realice sus búsquedas con Bing.
Los buscadores más relevantes que han surgido en internet han sido los buscadores genéricos mencionados. No obstante, han surgido también buscadores especializados en temas específicos. Por ejemplo, buscadores de personas (como 123people.com o paginasblancas.es), de empresas (como paginasamarillas.es o yellowpages.com), de programas (como softonic.com o shareware.com) o de direcciones (como guiarepsol.com o maps.google.com). Desgraciadamente, este tipo de buscadores no ha tenido fácil encontrar un hueco en este mercado dominado por muy pocos, lo que, en la mayoría de los casos ha desembocado en su cierre o anonimato.
La mayoría del tráfico web viene desde los buscadores. Por otro lado, la inmensa mayoría de los usuarios solo vemos la primera página de los resultados de una búsqueda.
En la actualidad. Inteligencia artificial
Después de estas primeras décadas de historia, el negocio de los buscadores ha quedado dominado indiscutiblemente Google. Aunque han aparecido nuevas ideas, generalmente han sido creadas o compradas por Google. Por otro lado, los cambios realizados en estos últimos años han ido más orientados a mejorar la rentabilidad de los buscadores que a mejorar la satisfacción de los usuarios con los resultados de sus búsquedas.
Para que nos hagamos una idea, la mayoría del tráfico web viene desde los buscadores. Por otro lado, la inmensa mayoría de los usuarios solo vemos la primera página de los resultados de una búsqueda, por lo que la lucha por estar en estas primeras posiciones es grande. Esto nos explica que los beneficios de los buscadores sean de miles de millones de dólares al año.
La situación de monopolio de Google es tal que más del 80% de las búsquedas en internet se llevan a cabo a través de esta plataforma. El único buscador que le hace algo de sombra a Google es Bing. La aparición de la inteligencia artificial y de chats de inteligencia artificial ha aportado algo de incertidumbre en esta lucha. No obstante, hay que recordar que tanto Google como sus competidores llevan años utilizando esta tecnología, solo está cambiando levemente el cómo se le presenta a sus usuarios.
Dicho de otra forma, la historia continúa.
Más información
Aquí se ha expuesto de forma resumida cuál ha sido la historia de los buscadores de internet, esto es, cómo se han ido produciendo los avances tecnológicos necesarios que han permitido el desarrollo de esta tecnología. Con suerte, se habrá sido capaz de generar dudas y crear curiosidad sobre este tema. En este blog se dispone de muchos otros contenidos relacionados. Por favor, utilice el buscador de contenidos que tenemos en la cabecera de este blog.
Estos son algunos otros artículos que pueden ser de interés:
- Breve historia de las redes sociales online
- Qué es ChatGPT y cómo funciona
- Cómo funciona la publicidad en internet
REF: INT-PG158
Me gustó mucho la información, la redacción es clara.
Muchas gracias Luciana. Muy amable. Saludos