
Bajo la superficie brillante de Internet repleta de vídeos, noticias y redes sociales late una realidad incómoda: la mayor parte de lo que se almacena y circula por la red es ruido, contenido inútil, basura digital. Aunque no se aprecie, este sustrato crece sin descanso y condiciona la utilidad de la red. No es solo que aumente el contenido vacío o falso, que también, sino que los datos nunca se borran, lo que hace que el 85% de Internet sea simplemente inútil. En este artículo se describe en qué consiste el vertedero de Internet, una acumulación masiva de residuos digitales que consume recursos, energía y atención sin aportar el más mínimo valor a la humanidad.
En este artículo veremos que la basura de Internet no es solo el spam, sino todo un ecosistema de datos y contenidos cuya existencia consume recursos sin aportar valor real. Desde el contenido duplicado hasta los textos generados automáticamente, las interacciones vacías o los datos que se almacenan sin que nadie los consulte, veremos un mapa conceptual que nos permita entender el problema.
Una gran parte de la basura de Internet es invisible. Son los datos oscuros formados por multitud de archivos de logs, copias, registros y documentos que nadie mira pero que ocupan servidores enteros. Estos son los residuos silenciosos del mundo digital, siempre encendidos, siempre consumiendo energía, siempre creciendo. Internet se está convirtiendo en un ecosistema pesado y difícil de gestionar.
Tampoco es menor el teatro de las apariencias de las redes sociales, lleno de interacciones vacías, likes automáticos, comentarios genéricos y tráfico generado por bots. Todo ello alimenta una ilusión de actividad que no refleja comportamientos humanos reales. Lo mismo ocurre con las granjas de SEO spam, fábricas de contenido irrelevante creadas simplemente para manipular buscadores y ocupar espacio, no para informar.
El artículo también repasa cómo se estudia este fenómeno, qué métricas permiten medirlo y cuál es su impacto invisible: desde el consumo energético hasta la degradación de la calidad informativa. El objetivo es ofrecer una visión completa de un problema que afecta tanto a la sostenibilidad digital como a nuestra capacidad de orientarnos en un entorno saturado.

Qué es la basura de Internet
La basura de Internet es el rastro de datos que circula o se almacena en la red sin aportar utilidad real. Es el subproducto inevitable de un ecosistema digital que prioriza la acumulación sobre la limpieza. Para entender su magnitud, basta con mirar nuestro propio entorno: versiones obsoletas de documentos, archivos duplicados por si acaso o capturas de pantalla olvidadas. Internet es, en esencia, ese mismo desorden multiplicado a escala global.
Podemos clasificar este vertedero digital en estas grandes categorías:
- El residuo invisible de los datos oscuros o dark data. La mayor parte de la basura digital es invisible para el usuario medio. Se trata de lo que se conoce como dark data o datos oscuros. Son los archivos de registro de actividad (conocidos como logs), copias de seguridad de versiones ya superadas y datos masivos de sensores (presencia, temperatura, consumo, etc.) que se almacenan indefinidamente sin ser consultados jamás. Estos datos son una basura silenciosa que no se ve, pero que ocupan centros de datos masivos y consumen energía de forma ininterrumpida, generando una huella ambiental constante por el simple hecho de existir.
- El relleno estructural de los datos ROT y el SEO excesivo. A nivel de contenido, la red sufre una acumulación de un tipo de datos conocidos como ROT por Redundantes, Obsoletos o Triviales. Esto incluye desde páginas web abandonadas hasta contenidos duplicados por miles de usuarios. A esto se suma el relleno estratégico que efectúan algunas webs que crean contenido exclusivamente para engañar a los algoritmos de búsqueda. Son piezas que no buscan informar, sino captar clics y ocupar espacio publicitario, degradando la calidad de la información disponible y obligando al usuario a navegar entre capas de ruido para encontrar datos de valor.
- Las interacciones vacías en redes sociales. Comentarios genéricos, respuestas automáticas, publicaciones hechas automáticamente solo para mantener presencia o contenido compartido sin ni siquiera haberlo leído. Todas estas comunicaciones forman parte de un teatro de apariencias que multiplica el volumen de datos sin añadir significado. Este comportamiento, humano o automatizado, alimenta algoritmos que premian la cantidad sobre la calidad, generando un círculo vicioso donde lo superficial se reproduce más rápido que lo valioso.
- El comportamiento malicioso. Internet es un medio de comunicación de bajo coste, lo que lo convierte en el escenario ideal para el mal. Hablamos de millones de correos no deseados (spam) y de comunicaciones masivas que saturan los servidores y los discos de respaldo. A menudo estos envíos están vinculados a prácticas maliciosas como el phishing, spoofing o el malware. Por otro lado, las prácticas delictivas como el ataque a servidores, el espionaje o los intentos de chantaje no solo generan una actividad extraordinaria por parte de los criminales, sino que fuerza a los servidores a mantener una actividad y capacidad de almacenamiento extra para defenderse de los primeros.
Lo cierto es que esta basura silenciosa del mundo digital está siempre creciendo, siempre encendida y siempre presente. Los algoritmos de inteligencia artificial no han hecho más que hacer crecer toda esta actividad generadora de basura. Al tener la capacidad de simular la actividad humana, están siendo muy utilizados para inflar métricas, manipular conversaciones o simplemente saturar servicios.
Dato curioso: Se estima que desde el año 2026, más del 90% del contenido nuevo de internet podría ser generado sintéticamente por inteligencia artificial.
Aunque un solo correo no deseado o un archivo log parezcan insignificantes, su acumulación forma una masa crítica que drena recursos energéticos y entierra el conocimiento útil bajo una montaña de desechos. La basura de Internet no es solo un problema de orden, es un desafío ecológico y funcional para el futuro de la red.
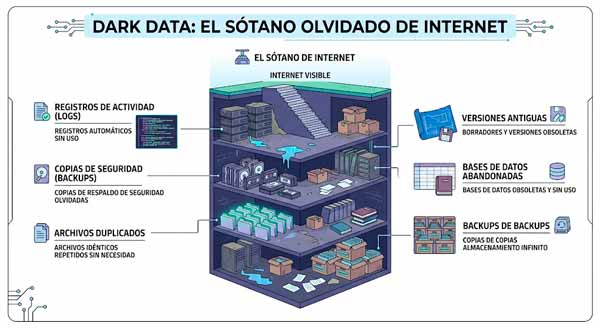
Los datos oscuros de los sótanos de Internet
No toda la información guardada en los servidores de Internet es accesible a sus usuarios. En los sótanos de esta ciudad digital se acumula un tipo de basura diferente: datos que nadie ve, pero que nadie borra. Estamos hablando de los archivos de registro de actividad (logs), copias de seguridad, archivos duplicados, versiones antiguas, bases de datos abandonadas o backups de backups. Estos datos oscuros o dark data son datos que existen, ocupan espacio y consume energía, pero que nadie usa. No es que sea necesariamente inútil, es que nadie la mira.
Si nos preguntamos quién genera este estrato de basura, esta es la respuesta:
- Sistemas de seguridad que registran cada evento, cada acceso, cada error, por si acaso. Esto incluye, por ejemplo, los archivos logs de los servidores y aplicaciones o los datos de sensores IoT (Internet de las cosas), registros de temperaturas, consumos o entradas y salidas.
- Equipos que guardan todas las versiones de un documento, por miedo a perder algo.
- Herramientas de copia de seguridad que replican datos sin políticas claras de caducidad.
- Migraciones tecnológicas que dejan islas de información huérfana en servidores antiguos.
Lo siguiente sería preguntar el por qué se hace esto. Estas son las posibles respuestas:
- La cultura del guardarlo todo. Las tecnologías de big data y cloud han hecho que sea barato guardar datos, pero gestionar estos datos sigue siendo caro.
- Los sistemas heredados. La tecnología evoluciona de forma constante, lo que fuerza a actualizar y cambiar los sistemas. Estas migraciones dejan enormes silos de datos muertos que resulta más barato dejarlos abandonados que gestionarlos adecuadamente. Algo similar a lo que ocurre en el mundo físico.
- IoT y automatización. Millones de dispositivos están generando registros (logs) de forma constante que casi nadie revisa ni elimina. Cualquier dispositivo IoT de casa o de la oficina (calefacción, alarmas, lavadora, videovigilancia, etc.) guarda registros de toda su actividad que los va almacenando en Internet.
El problema no es solo que estos datos basura consuman energía y cuesten dinero por el hecho de existir, sino que, adicionalmente, los datos oscuros reducen la eficiencia operativa de los centros de datos entre un 15 y 20%. En una encuesta global de Splunk a más de 1.300 responsables de TI (área de tecnología de la información en las empresas), el 60% afirmó que la mitad o más de sus datos son datos oscuros, y un tercio dijo que el 75% o más lo es.
Los datos oscuros son un vertedero silencioso, porque casi nadie tiene una percepción directa de esos datos. No obstante, la infraestructura que los mantiene vivos sí tiene coste económico y ambiental. Por aportar más datos, un estudio de Veritas estimó que el almacenaje de los dark data entre 2016 y 2020 costó unos 3,3 billones de dólares a nivel mundial.
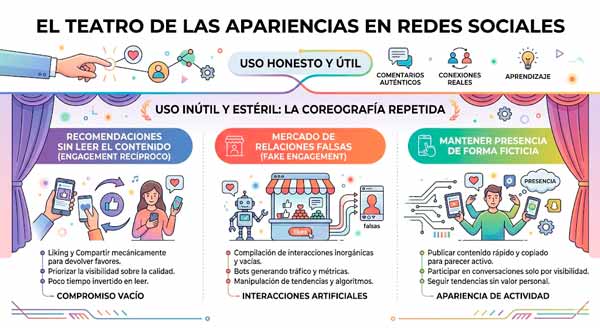
El teatro de las apariencias: interacciones vacías
Las redes sociales son lugares muy coloridos y ruidosos. A primera vista parece un lugar lleno de vida, con multitud de likes, comentarios y compartidos. Pero si se observa con calma, se ve una coreografía repetida: mensajes vacíos que nadie lee, comentarios genéricos automatizados y reacciones que se dan por compromiso sin leer el contenido.
No solo los bots crean tráfico basura en las redes sociales, existen muchas publicaciones de humanos que no tienen ningún sentido, bien porque el contenido se ha creado en segundos con algún corta y pega o bien porque la propia dinámica social de participar en las conversaciones de otros nos obliga a hacer comentarios o recomendar publicaciones que no tenemos tiempo de leer. La basura en redes sociales se ha convertido en una parte estructural del ecosistema digital. Aunque no existe una cifra única que mida todo este ruido, sí hay estudios sólidos que analizan por separado el volumen de bots, del de las interacciones falsas y del mercado que las sostiene.
El teatro de las apariencias está compuesto básicamente por los siguientes comportamientos:
- Recomendaciones sin leer el contenido. Es lo que se conoce como engagement recíproco o compromiso recíproco. Ocurre cuando un usuario recomienda el contenido de otros esperando que estos recomienden el suyo. No es estrictamente automatizado, pero sí genera interacciones sin valor informativo. Sencillamente se dan respuestas automáticas del tipo ¡Genial! o ¡Enhorabuena! para dar la apariencia de una relación activa y significativa.
- Mercado de relaciones falsas (fake engagement). Existe un mercado de interacciones en redes sociales donde se compran o intercambian likes, retuits o recomendaciones. Los estudios sobre este mercado muestran un ecosistema subterráneo masivo de servicios que venden interacciones falsas. Un análisis de 86 paneles de Social Media Management (SMM) detectó 61.000 servicios distintos relacionados con engagement artificial. Estos servicios permiten comprar likes, seguidores, comentarios y recomendaciones, lo que alimenta la cultura de interacción vacía.
- Mantener presencia ficticia. A veces interesa mantener una presencia en determinados entornos sin estar realmente interesado en su contenido. El objetivo es cumplir con expectativas sociales. Para ello se realizan comentarios irrelevantes, acciones mínimas para mostrar presencia o se publica algún contenido nada elaborado que no contiene información real. Aunque este comportamiento es humano en cualquier entorno, no por ello deja de formar parte del ruido social que infla artificialmente la actividad de las plataformas.
La actividad superficial en redes sociales forma un ecosistema de tráfico social vacío que distorsiona la percepción de conversación real. Aunque este fenómeno ha sido estudiado, no existe una cifra única que cuantifique todo el teatro de las apariencias. Lo cierto es que en el entorno de las redes sociales existen distintas capas humanas, automatizadas y algorítmicas que son difíciles de separar. Lo que sí tenemos son estudios sólidos sobre engagement falsos, comentarios automatizados y comportamientos sociales de baja calidad, que permiten trazar un mapa bastante claro del problema.
La conclusión es que las cifras demuestran que el volumen de interacciones falsas es sistemático y global. Además, la literatura sobre fraude en redes sociales confirma que el engagement falso afecta a métricas, campañas y decisiones empresariales. De hecho, se puede decir que el engagement falso es masivo, organizado y económicamente significativo. Para el que esté interesado, estos tres estudios pueden darle una pista: Fake social media engagement services, Fake-follower campaigns on social media o Social Media Fraud.
Las granjas del SEO spam
Más allá de los datos oscuros, de la guerra de las vanidades o de la creciente participación de los bots y la IA en Internet, hay otro tipo de basura más sutil: el contenido que parece contenido… pero que no lo es. Son los artículos que repiten una y otra vez lo mismo, reescritos con otras palabras; los vídeos que rellenan minutos sin aportar ideas; las páginas creadas solo para que un anuncio aparezca en algún lugar. Es lo que se conoce como SEO spam o spamdexing.
El SEO spam es el conjunto de técnicas manipuladoras que intentan engañar a los motores de búsqueda para obtener un mejor posicionamiento del que una página merece. Es una forma de basura digital porque genera contenido irrelevante, enlaces artificiales y señales falsas que saturan la web sin aportar valor real. De hecho, los motores de búsqueda lo consideran una violación directa de sus directrices y, en general, son prácticas no éticas, engañosas y penalizables.
Las modalidades más habituales del SEO spam incluyen:
- Keyword stuffing. Consiste en rellenar textos con palabras clave de forma antinatural para inflar artificialmente la relevancia de esa web.
- Contenido duplicado o automático sin valor. Son páginas generadas en masa, textos repetidos o creados por máquinas solo para ocupar espacio.
- Enlaces ocultos o engañosos. Son enlaces invisibles al usuario pero detectables por los buscadores.
- Spam en comentarios y foros. Se trata de incluir enlaces en los comentarios de blogs o de redes sociales para simular que un sitio web al que va dirigido despierta más interés del real. La idea es mejorar la autoridad de un sitio.
- Doorway pages y cloaking. Son páginas que discriminan si quien los visita es un buscador o un usuario normal y muestra información distinta en cada caso.
- Granjas de enlaces. Son redes de sitios creados únicamente para intercambiar enlaces y elevar artificialmente la autoridad de un sitio web.
- Abuso de rich snippets y metadatos. Manipula los metadatos de las páginas HTML para mejorar artificialmente la apariencia de la página frente a los buscadores. Los rich snippets son códigos (snippets o fragmentoe) que se incluyen en la web para ofrecer información adicional a los buscadores, como las estrellas de valoración, precios, imágenes, etc.
- Scraping y republicación masiva. Estas páginas se forma copiando el contenido de otros sitios sin ningún tipo de permisos. El objetivo es aportar volumen de contenido que atraiga tráfico, aunque sea fraudulento.
Estas prácticas no solo generan ruido y degradan la calidad de los resultados de búsqueda, sino que hacen que los usuarios pierdan más tiempo en encontrar lo buscado. El SEO spam contribuye al vertedero de Internet porque: multiplica el contenido sin valor, crea millones de páginas redundantes, genera tráfico artificial, distorsiona la visibilidad de la información útil y obliga a los buscadores a procesar y almacenar datos falsos.
Es difícil cuantificar el volumen de este tipo de datos porque no es fácil definir los límites que diferencia una información pobre de una información basura. En cualquier caso, se trata de información que no espera ser leída, que no ha sido creada para las personas, sino para manipular a las máquinas. Su impacto es silencioso pero masivo, y forma parte del ruido estructural que hace que Internet sea cada vez más difícil de navegar.
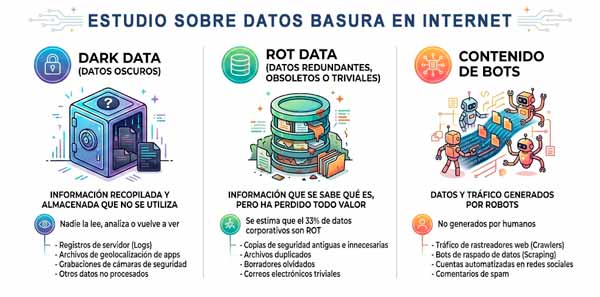
Cómo se estudia la basura de Internet
La basura de Internet no es solo una metáfora, es una realidad física y estadística que la literatura científica y técnica intenta cuantificar. No existe un sensor único para este fenómeno, sino una serie de investigaciones rigurosas que analizan las distintas capas del vertedero invisible. La primera línea de investigación se centra en los datos en reposo, aquellos que habitan en servidores sin que nadie los consulte, sin cumplir función alguna. Como se ha descrito anteriormente, estamos hablando de:
- Dark Data (Datos Oscuros): Según estimaciones de consultoras como Gartner, hasta el 80% de los datos corporativos entran en esta categoría. Son subproductos de la actividad digital (registros de servidores, geolocalizaciones crudas o grabaciones de seguridad) que se almacenan por si acaso, consumiendo energía y espacio físico sin ser jamás consultados.
- ROT Data: Esta es la basura doméstica y corporativa más común. Es información que se sabe qué es, pero que ha perdido todo su valor. Se estima que el 33% de los servidores corporativos están saturados exclusivamente por datos ROT. Sus siglas definen perfectamente su naturaleza:
- Redundantes: Copias del mismo archivo en tres carpetas distintas, el mismo meme enviado a cinco grupos de WhatsApp o archivos adjuntos duplicados en hilos de correos.
- Obsoletos: La versión ‘v1_final_borrador’ de un documento cuando ya vas por la ‘v20’, copias de normativas legales que ya no existen o fotos de un evento de 2012 que ya no tiene relevancia.
- Triviales: Información sin valor intrínseco que nunca tuvieron valor real. Por ejemplo, los mensajes de cortesía en emails («Gracias», «Recibido»), capturas de pantalla accidentales o tráfico técnico de mantenimiento (pings).
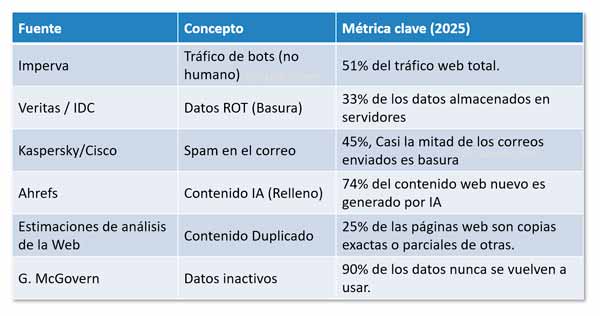
Por otro lado, también se está midiendo el flujo de la basura en movimiento. El informe de referencia mundial es el Imperva Bad Bot Report. En su análisis de 2025, el informe arroja una cifra histórica: los bots ya generan más del 50% del tráfico global de Internet, desplazando por primera vez a la actividad humana. Este volumen masivo de datos no busca el consumo humano, sino el scraping masivo, el fraude publicitario o la saturación de servicios, creando una red que trabaja mayoritariamente para hablarse a sí misma, sin valor humano real.
Este auge de la automatización ha validado lo que en 2010 nació como una teoría de la conspiración: la Dead Internet Theory o teoría del Internet muerto. Lo que antes era un debate en foros de nicho (como 4chan y Reddit), hoy es una observación sociológica y técnica seria: la percepción de que la red se ha convertido en un teatro de interacciones donde unos bots publican contenido para que otros bots lo comenten y compartan. En este Internet zombis la mayor parte de la interacciones no son entre humanos, sino de algoritmos e IA. El usuario humano es un espectador marginal que consume basura creada por máquinas para otras máquinas.
A este fenómeno se le ha sumado recientemente el concepto de datos sintéticos o AI Slop (chapapote de IA). Se trata de los datos creados por inteligencias artificiales (IA) con la finalidad de servir de sustitutos o complementarios de los datos auténticos cuando estos son escasos, sensibles o difíciles de obtener. Aunque los datos sintéticos tienen usos legítimos en ciencia, su uso masivo para generar relleno en buscadores y redes sociales está creando un bucle infinito de baja calidad. Además, este contenido desplaza la creatividad humana y satura la red de información superficial, convirtiéndose en la forma más moderna y peligrosa de residuo digital.
Las métricas más relevantes
Para dimensionar la gravedad del problema, debemos abandonar los adjetivos y observar las métricas técnicas ofrecidas para los años 2025 y 2026. Los estudios más rigurosos segmentan este vertedero en tres frentes críticos:
- En relación al tráfico: El fin de la hegemonía humana. Según el Imperva Bad Bot Report (2025), hemos cruzado un punto de no retorno: los humanos somos ahora la minoría en la red. Como ya se ha indicado, por primera vez, más de la mitad del tráfico global (el 51%) es generado por máquinas. De ese volumen, un 37% corresponde a bad bots (ataques de fuerza bruta, scraping agresivo y bots de spam) y solo el 14% es generado por bots buenos (buscadores, servicios de gestión de la red, etc). Esto implica que más del 50% de la infraestructura física del planeta (cables submarinos, satélites y centros de datos) está operando para mover información que ningún ser humano ha solicitado ni consumirá jamás.
- Sobre el almacenamiento. Los datos oscuros y ROT. Si el tráfico es el ruido, el almacenamiento es el vertedero. Aquí, la empresa de gestión de datos Veritas y la consultora IDC lideran las investigaciones sobre el dark data. Según informes consolidados para 2025, el 52% de los datos son datos oscuros (dark data), el 33% son datos de tipo ROT (ROT Data) y solo el 15% es información útil y limpia. Esto significa que, si se estima que el volumen total de datos almacenados en los servidores de Internet en 2025 era de 175 ZB (zettabytes, 10²¹ bytes), se ha estado gastando energía para mantener cerca de 150 zettabytes que es basura digital.
- Sobre el contenido. Se habla de la inflación de contenido generada por la IA. Con la explosión de la IA generativa, el concepto de ‘contenido de relleno’ ha mutado. Un análisis de Ahrefs realizado en abril de 2025 sobre casi un millón de páginas web recién publicadas reveló que el 74.2% de las nuevas páginas web contenían fragmentos significativos o eran totalmente generadas por IA sin revisión humana. Siguiendo con la teoría del Internet muerto, investigadores del Copenhagen Institute for Futures Studies postulan que para 2030, el 99% del contenido de Internet será generado por máquinas, creando un bucle de retroalimentación donde las IA se entrenarán con los contenidos generados por otras IA.
Permítanme que insista con otros datos de estudios sobre la actividad de la IA en Internet. Por ejemplo, en Arxiv hicieron una revisión de más de 500 publicaciones sobre la detección de bots y confirmaron el papel determinante que están jugando los bots en la distribución masiva de mensajes. Un estudio sobre marketing de influencers realizado por la Universidad de California analizó más de 65 millones de interacciones y detectó patrones claros de bots que generan comentarios cortos, repetitivos y de baja calidad para inflar métricas. Por último, investigaciones sobre redes de bots sociales describen que existen ejércitos de cuentas automatizadas capaces de generar miles de interacciones falsas para simular popularidad o consenso.
El coste de mantener la basura digital
La basura digital no flota en una nube etérea, sino que descansa en centros de datos equipados con servidores que necesitan mantenerse a una temperatura adecuada y estar alimentados con energía eléctrica. Lo más inquietante es que toda esta basura digital, mensajes que nadie pidió, tráfico de bots, contenido de relleno, interacciones vacías o datos olvidados tiene una capacidad única de autorreplicarse. Por ejemplo, ese spam que no borraste se duplica en copias de seguridad y el contenido de relleno sirve de base para que otras IA generen aún más relleno. El resultado es un ecosistema de redundancia obligado a sobredimensionar la infraestructura global, no para albergar conocimiento, sino para sostener lo que nadie se atreve a borrar.
Aunque no hay un estudio completo sobre el impacto de la basura digital en el consumo eléctrico o en la huella de carbono, sí hay datos aislados que nos permiten hacernos una idea. Por ejemplo, la ONU advierte que el auge digital incrementa significativamente el consumo energético global, especialmente por el almacenamiento y el procesamiento de los datos (ver informe de UN News). Se habla de que un gigabyte de almacenamiento en la nube puede consumir hasta unos 7 kWh al año en energía (servidor + refrigeración). En este sentido, la Agencia Internacional de la Energía (IEA) estima que para este año 2026, el consumo de los centros de datos se acercará a los 1,050 Teravatios-hora (TWh), convirtiendo a la infraestructura digital en el quinto país que más energía consume en el mundo, por encima de Japón.
Por otro lado, Greenpeace señala que existe una huella oscura, huella de carbono, asociada a los datos invisibles que almacenamos sin usar (ver informe de Greepeace). Como podemos sospechar, todo este consumo eléctrico inútil contribuye al aumento de la huella de carbono digital. En este último informe de Greenpeace se afirma que un solo archivo de 1 MB genera aproximadamente 19 gramos de CO2 o que un simple correo electrónico tiene una huella de 4 gramos de CO2. Por otro lado, un estudio publicado en el South African Journal of Information Management (2025) señala que los datos oscuros generan más de 5.8 millones de toneladas de CO2 al año.
Si necesita más referencias, el autor y analista Gerry McGovern, una referencia mundial en estos temas, en su libro World Wide Waste ofrece cálculos técnicos sobre el desperdicio. Por ejemplo, estima que el correo spam global genera una huella de carbono equivalente al que producen 1.6 millones de coches circulando durante un año o que hasta el 90% de los datos digitales no se vuelven a consultar nunca a partir de los tres meses después de su creación.

Conclusiones
Sabemos con claridad que la mayor parte de los datos almacenados en Internet son inútiles, que mantenerlos consume energía de forma constante y que esto contribuye al impacto ambiental del ecosistema digital. Además, la tendencia a seguir almacenando datos inútiles es creciente y preocupante.
Aunque no existe un estudio global que analice la basura existente o su impacto en su conjunto, sí existen multitud de estudios que han cuantificado aspectos concretos de esta basura digital. Estos trabajos demuestran que la basura digital no es un accidente, sino un subproducto inevitable de las plataformas que premian la cantidad por encima de la calidad. Simplificando mucho las cifras publicadas, se puede decir que como el 50% del tráfico de Internet es basura y que más del 80% de los datos almacenados en Internet son datos oscuros que no se usan.
En resumen: más del 80% de lo que guardamos en los servidores del mundo es, en términos prácticos, ruido o basura.
Por si no fuera suficiente, con el auge de la IA generativa, el problema ha entrado en una nueva fase. Ahora no solo almacenamos basura humana, sino también basura sintética, que crece más rápido que la humana. Redes sociales como Moltbook o SocialIA, diseñadas para que interactúen agentes de IA sin interacción humana directa, amplificarán la dinámica de creación de basura debido a tres factores: volumen, velocidad y vacío de valor. Parece evidente que lo humano empieza a diluirse en Internet.
El problema no es solo la autenticidad, sino el ruido. Cuando casi todo lo que se publica es sintético, lo valioso queda enterrado bajo capas de contenido automático. Los buscadores se saturan, las redes sociales se llenan de publicaciones sin propósito y los algoritmos se alimentan de señales falsas que ellos mismos han generado. A esta avalancha se suma la parte más silenciosa del vertedero: el dark data.
El resultado es un Internet que crece, sí, pero hacia dentro, como un organismo que acumula capas de tejido muerto. Un espacio donde la abundancia no significa riqueza, sino saturación; donde la información no ilumina, sino que enturbia; donde la inteligencia artificial no solo crea contenido, sino también basura. Y en ese paisaje, la tarea más difícil ya no es acceder a la información, sino distinguir lo que importa de lo que sobra.
Más información
En este artículo se ha abordado el tema de cómo crece la basura digital que se acumula en Internet. Espero que le haya resultado de interés. Si busca inspiración o simplemente le interesan estos temas, en este blog se dispone de otros muchos contenidos relacionados. Por favor, utilice el buscador de contenidos que tenemos en la cabecera.
Por otro lado, estos son algunos otros artículos que pueden ser de interés:
- Qué es la IA agéntica. La revolución de los agentes autónomos que piensan, deciden y actúan por ti
- Quién controla Internet. Organizaciones que dirigen la red global
- Qué significa Big Data, para curiosos
Bibliografía
Aunque los contenidos de este blog tienen un propósito divulgativo, la verificación de las fuentes es una tarea que nos tomamos con seriedad. No obstante, al ser un blog sin fines de lucro, nos vemos obligados a operar de manera austera, lo que implica no utilizar tiempo a referenciar exhaustivamente cada dato presentado. No obstante, si necesita verificar las fuentes, estas son algunas de las utilizadas:
- «The real cost of legacy data. Managing the ROT«. Ground Labs, revisado en marzo de 2026. https://groundlabs.com/blog/legacy-data-management
- «Why ROT Data Must be Effectively Managed: Definition and Best Practices«. 1touch.io, revisado en marzo de 2026. https://www.1touch.io/blogs/why-rot-data-must-be-effectively-managed-definition-and-best-practices
- «Más de 50 estadísticas sobre seguridad en la nube en 2025«. Sentinel One, revisado en marzo de 2026. https://www.sentinelone.com/es/cybersecurity-101/cloud-security/cloud-security-statistics/
- «Email Spam Statistics 2026«. DeBounce, revisado en marzo de 2026. https://debounce.com/blog/email-spam-statistics/
- «Spam y phishing en 2024«. Kaspersky, revisado en marzo de 2026. https://www.kaspersky.com/about/press-releases/kaspersky-reports-nearly-900-million-phishing-attempts-in-2024-as-cyber-threats-increase
- «What Percent of Internet Traffic is Bots?«. SOAX, revisado en marzo de 2026. https://soax.com/research/what-percent-of-internet-traffic-is-bots
- «The impact of digital waste«. Milgro, revisado en marzo de 2026. https://www.milgro.eu/en/blog/digital-waste
- «The Hidden Cost of Digital Life«. Digital Cleanup Day, revisado en marzo de 2026.
https://www.digitalcleanupday.org - «Digital waste sustainability: Data hoarding is killing the planet«. Evergreen Analytic Partners, revisado en marzo de 2026. https://evergreenanalyticspartners.com/digital-waste-sustainability/
- «La oscura huella digital«. Greenpeace España, revisado en marzo de 2026. https://es.greenpeace.org/es/noticias/huella-digital/
- «El boom digital amenaza al medio ambiente«. UN News, revisado en marzo de 2026. El boom digital amenaza al medio ambiente | Noticias ONU
- «El lado oscuro de la era digital«. Diario Responsable, revisado en marzo de 2026. https://diarioresponsable.com/noticias/37152-el-lado-oscuro-de-la-era-digital-la-amenaza-de-la-basura-tecnologica
- «What is dark data?«. IBM, revisado en marzo de 2026. https://www.ibm.com/topics/dark-data
- «Dark Data Statistics 2025–2026«. World metrics, revisado en marzo de 2026. https://worldmetrics.org/dark-data-statistics/
- «Unlocking the Power of Dark Data (2025)«. Lex Data Labs, revisado en marzo de 2026. https://www.lexdatalabs.com/post/unlocking-the-power-of-dark-data
- «Data that is stored and not used has a carbon footprint (2025)«. The Conversation, revisado en marzo de 2026. https://theconversation.com/data-that-is-stored-and-not-used-has-a-carbon-footprint-how-companies-can-manage-dark-data-better-262966
- «Spamming». Wikipedia, revisado en marzo de 2026. https://en.wikipedia.org/wiki/Spamming
- «Spam Statistics By Volume, Countries Of Origin and Daily Numbers«. Sci Tech Today, revisado en marzo de 2026. https://www.sci-tech-today.com/stats/spam-statistics/
- «Spam Statistics«. Anti Spam Engine, revisado en marzo de 2026. https://antispamengine.com/spam-statistics/
- «Spam Email Statistics». World Metrics, revisado en marzo de 2026. https://worldmetrics.org/spam-email-statistics/
- «World Wide Waste«. Gerry McGovern . gerrymcgovern.com/books/world-wide-waste
- «Bad Bot Report» (Edición 2025)». Imperva, revisado en marzo de 2026. imperva.com/resources/resource-library/reports/2025-bad-bot-report/
- «Web-scraping AI bots cause disruption for scientific databases and journals«. Nature, revisado en marzo de 2026. https://www.nature.com/articles/d41586-025-01661-4
- “Disinformation Spillover: Uncovering the Ripple Effect of Bot-Assisted Fake Social Engagement”. MIS Quarterly, revisado en marzo de 2026. https://misq.umn.edu/misq/article-abstract/48/3/847/2308/Disinformation-Spillover-Uncovering-the-Ripple
- “Bots and baddies: supporting the integrity of online survey research”. Springer, revisado en marzo de 2026. https://link.springer.com/article/10.1007/s11135-024-02001-w
- «The Databerg Report: Identifying the cost of Redundant, Obsolete, and Trivial data». Veritas, revisado en marzo de 2026. https://www.veritas.com/news-releases/2016-03-15-veritas-global-databerg-report-finds-85-percent-of-stored-data
- «99th Day: A Warning About Technology«. Gerry McGovern. https://gerrymcgovern.com/books/99th-day/
- «Unsupervised detection of coordinated fake-follower campaigns on social media«. Springer Nature, revisado en marzo de 2026. https://link.springer.com/article/10.1140/epjds/s13688-024-00499-6
- «Challenges in machine learning-based social bot detection: a systematic review«. Springer Nature, revisado en marzo de 2026. https://link.springer.com/article/10.1007/s44163-025-00448-w
- «Social Media Bot Detection Research: Review of Literature«. Universidad de Novo Mesto, revisado en marzo de 2026. https://arxiv.org/pdf/2503.22838
- «Understanding bot networks and fake engagement«. Cambridge Analytica, revisado en marzo de 2026. https://cambridgeanalytica.org/knowledge/understanding-bot-networks-and-fake-engagement-49838/
- «Dead Internet theory«. Wikipedia, revisado en marzo de 2026. https://en.wikipedia.org/wiki/Dead_Internet_theory
- «An analysis of fake social media engagement services«. Universidad Carlos III, revisado en marzo de 2026. https://e-archivo.uc3m.es/entities/publication/a2630f60-fed0-4484-bfc7-a0b303504501
- «Amenazados por la basura tecnológica: la huella oscura de los dispositivos digitales«. Green Peace, revisado en marzo de 2026. https://es.greenpeace.org/es/noticias/huella-digital/
- «La basura digital: qué es y cómo reducirla«. Uniblog, revisado en marzo de 2026. https://uniblog.unicajabanco.es/la-basura-digital-que-es-y-como-reducirla
- «El boom digital amenaza al medio ambiente«. Naciones Unidas, revisado en marzo de 2026. https://news.un.org/es/story/2024/07/1531106
- «La basura digital generada por la IA amenaza la calidad de internet«. UOC, revisado en marzo de 2026. https://www.uoc.edu/es/news/2025/basura-digital-generada-por-la-ia-amenaza-la-calidad-internet