
Para transmitir audio por internet es necesario convertir la señal analógica en información digital. Esto es lo que se conoce como codificación de la voz o del audio. Existen distintas técnicas de codificación y decodificación de la voz o codecs. Para que los equipos de distintos fabricantes sean compatibles entre si, es necesario disponer de técnicas normalizadas que todos ellos entiendan. Veamos cuáles son los estándares de codec de audio utilizados en internet.
Desde que Alec H. Reeves tuviera la idea de digitalizar la señal de la voz en 1937, se han ido desarrollando sistemas cada vez más eficientes y eficaces. Desde un principio, el objetivo ha sido el mismo: conseguir un sistema que ofrezca una buena calidad de sonido con el menor ancho de banda posible. El tiempo y el esfuerzo de muchos investigadores y entidades han propiciado que esta marca se haya venido superando una y otra vez. Sin embargo, este esfuerzo resultaría banal si el mercado no se hubiera puesto de acuerdo en utilizar sistemas compatibles entre sí.
El organismo regulador que ha jugado el papel más destacado con los codecs de voz ha sido la Unión Internacional de Telecomunicaciones, sector de normalización de las telecomunicaciones, más conocida como UIT-T o por sus siglas en inglés ITU-T.
Necesidad de codecs normalizados
A diferencia de las redes telefónicas tradicionales, formadas por operadores interconectados donde cada uno de ellos controla su red de forma absoluta, internet está formada por distintos proveedores de infraestructuras sobre los que otros proveedores independientes ofrecen sus servicios. Además, un mismo servicio puede necesitar de la colaboración de distintos proveedores.
Por ejemplo, se puede iniciar una llamada de VoIP en un proveedor local para llamar a un terminal que se encuentra en otro país atendido por otro proveedor de servicio con terminales de fabricantes diferentes. Esto hace que el trabajo de regulación de los codec de audio sea fundamental.
Una particularidad que se puede dar con la VoIP es que una misma comunicación de voz podría utilizar distintos codecs en distintos tramos de la comunicación. Aunque esto puede afectar a la calidad final de la conversación, la gran noticia es que se podrá llevar a efecto. Por otro lado, los recursos dedicados a la VoIP son cada vez mayores, por lo que las comunicaciones son, en general, de una buena calidad.
Otra particularidad de los codecs es que están optimizados para reproducir el habla, sin embargo, a veces se necesita transmitir otro tipo de información distinta de la voz. En estos casos, los proveedores de servicio suelen buscar alternativas que garanticen la calidad y no limiten, en lo posible, los servicios a los que los usuarios de las redes telefónicas tradicionales estamos acostumbrados.
Las recomendaciones de la UIT-T que se ocupan de normalizar la codificación de la voz son las de la serie G.700.
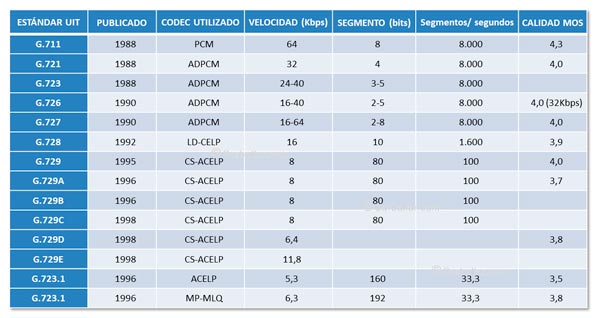
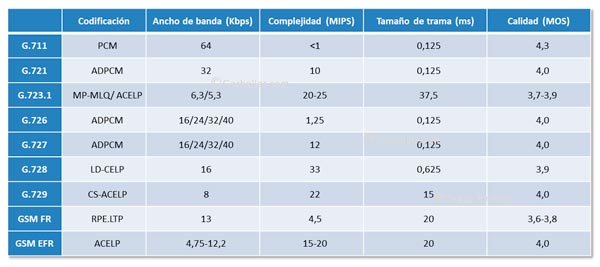
G.711. PCM
En 1937, el mencionado Alec Harley Reeves, un brillante ingeniero británico que trabajaba en Francia para la International Western Electric Company desarrolló la idea de digitalizar la señal de voz para evitar los ruidos y distorsiones a las que se ven sometidas las comunicaciones analógicas. El resultado fue la técnica de codificación de la voz conocida como PCM (Pulse Code Modulation, ‘Modulación por codificación de pulsos’). Como, por otro lado, las comunicaciones analógicas podían ser interceptadas fácilmente, las primeras aplicaciones de este sistema de audio digital fueron militares. No obstante, la codificación PCM no se haría popular hasta los años 60, después de la invención del transistor. El sistema de digitalización PCM quedaría normalizado por el UIT-T con el modelo G.711, publicado en 1972.
Curiosamente, Reeves, quien también es considerado precursor del radar, se interesó también por las comunicaciones paranormales, como la telepatía o las comunicaciones con el más allá; pero en este campo no consiguió avances.
PCM es un codec de audio de forma de onda que utiliza una velocidad de muestreo de 8.000 Hz. Aunque en un principio utilizaba una cuantificación uniforme de 12 bits por muestra, lo que produce un ancho de banda de 96 Kbps, posteriormente se desarrollaron distintos tipos de cuantificaciones no uniformes que sólo necesitan 8 bits por muestra, lo que nos lleva a un ancho de banda de 64 Kbps.
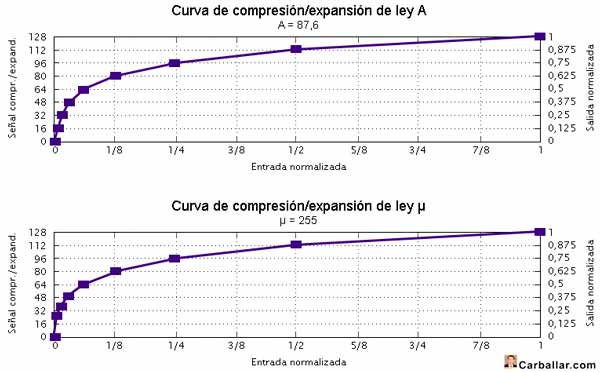
G.711 utiliza una cuantificación no uniforme en dos variantes:
- Ley μ (Ley mu). Utilizada, fundamentalmente, en Estados Unidos y Japón.
- Ley A. Propuesta por K. Cattermole en 1962 y utilizada en Europa y el resto del mundo.
Lo que diferencia a estas dos variantes es la forma de realizar la cuantificación.
G.726. PCM diferencial y adaptativo
Como se ha visto, el sistema PCM transmite muestras individuales para reconstruir en destino la forma de onda original. Este sistema no considera ningún tipo de relación entre muestras consecutivas. No obstante, el hecho es que la señal de la voz va evolucionando de forma suave. Esto quiere decir que si se tienen en cuenta las últimas muestras, se puede predecir, aproximadamente, el valor que va a tener la muestra siguiente. Por tanto, bastará con transmitir la diferencia entre el valor calculado y el valor real de la muestra para que en el destino puedan reconstruir la señal original. Como en el otro extremo se utiliza el mismo modelo de predicción, al recibir el valor de la diferencia se consigue reproducir la señal original.
La gran ventaja de esta técnica de codec de audio es que la información que se necesita transmitir es mínima, reduciéndose significativamente el ancho de banda necesario (se queda en un 25% comparado con PCM).
Esta técnica se conoce como PCM diferencial o DPCM (Differential PCM o ‘PCM diferencial’).
Por otro lado, en la idea de reducir aún más el ancho de banda necesario se pensó que los parámetros de predicción se podrían ir adaptando (modificando según los resultados que se van obteniendo) para minimizar el error de predicción. Como en ambos extremos se utiliza el mismo modelo de predicción, se consigue el mismo resultado pero con menos información que transmitir. A esta técnica se la conoce como DPCM adaptativo o ADPCM.
El sistema ADPCM está recogido en el estándar G.721 de la UIT-T. Con este estándar se consigue un canal de voz con calidad similar a G.711 utilizando tan sólo 32 Kbps. G.721 fue sustituido en 1984 por G.726, el cual utiliza canales de 16, 24, 32 y 40 Kbps con diferentes niveles de calidad.
Tanto los sistemas DPCM y ADPCM son del tipo codec de forma de onda.
G.728. LD-CELP
A principio de los años 80 empezaron a aparecer los primeros codecs híbridos. Este es el caso de los sistemas de codificación de la voz conocidos como AbS (Analysis by Synthesis, ‘Análisis por síntesis’), los cuales se basan en utilizar una lista de modelos de señal de forma que sólo tienen que transmitir al destino el código de identificación del modelo que le va correspondiendo a cada muestra de señal.
El primer sistema AbS apareció en 1982 y se conoce como MPE (Multi-Pulse Excited, ‘Excitación multipulso’). En 1986 aparecería una variante conocida como RPE (Regular-Pulse Excited, ‘Excitación de pulso regular’), utilizada por el sistema europeo de telefonía móvil GSM (Global System for Mobile communications, ‘Sistema global para las comunicaciones móviles’), consiguiendo una alta calidad de voz con tan sólo 13 Kbps. A este sistema de codec de audio se lo conoce como GSM-FR (GSM Full rate, ‘GSM de velocidad completa’).
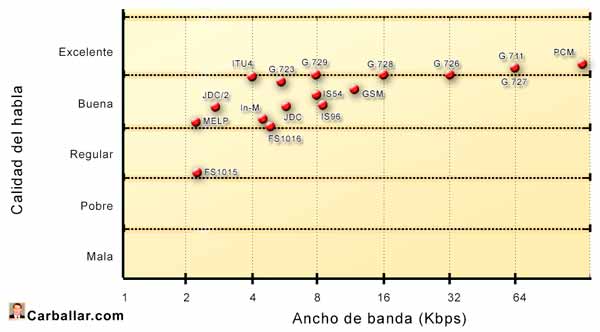
El inconveniente de los sistemas MPE y RPE es que no pueden mantener una buena calidad de voz a velocidades inferiores a 10 Kbps. Este inconveniente fue superado por un nuevo codec conocido como CELP (Code-Excited Linear Predictive, ‘Predicción lineal con excitación por código’).
La recomendación UIT-T G.728 describe una modalidad del sistema CELP conocida como LD-CELP (Low-Delay CELP, ‘CELP de bajo retardo’). G.728 agrupa cinco muestras de voz para determinar mejor el vector del libro de códigos que le corresponde. Este proceso de análisis genera un retardo adicional de menos de un milisegundo, de ahí el nombre.
LD-CELP utiliza un libro de códigos de 1.024 entradas, por lo que el índice del libro de códigos sólo necesita 10 bits (RPE utiliza 47 bits). Como G.728 toma 8.000 muestras por segundo y envía 10 bits por cada 5 muestras, el ancho de banda necesario es de 16 Kbps. La calidad de voz conseguida es 3,9 MOS.
El gran inconveniente del sistema G.728 es que necesita procesadores potentes que sean capaces de llevar a cabo el análisis necesario, lo que hace que raramente sea utilizado debido a su mayor coste.
G.723.1. ACELP y MP-MLQ
En la carrera por conseguir disminuir el ancho de banda necesario manteniendo unos buenos niveles de calidad, en 1995 se publicó el nuevo estándar G.723.1 que consigue velocidades de 6,3 y 5,3 Kbps con calidades de voz 3,8 y 3,5 respectivamente.
Estos sistemas de codificación de la voz realizan 8.000 muestras por segundo que cuantifican con 16 bits. A continuación toman cuatro grupos de 60 muestras (3.840 bits) para determinar los coeficientes de predicción apropiados. Los parámetros que identifican el modelo del libro de códigos utilizado se envían de acuerdo a estos dos sistemas:
- MP-MLQ (Multipulse Maximum Likelihood Quantization, ‘Cuantificación multipulso de máxima probabilidad’). Consigue un ancho de banda de 6,4 Kbps enviando la información comprimida en tramas de 192 bits (8.000 x 16 x 192 / 3.840 = 5.333).
- ACELP (Algebraic Code-Excited Linear Prediction, ‘Predicción lineal con excitación por código algebraico’). Consigue reducir el ancho de banda necesario a 5,3 Kbps al enviar la información comprimida en tramas de 160 bits (8.000 x 16 x 160 / 3.840 = 5.333). Lo que aporta ACELP es que las entradas del libro de códigos ya no vienen dadas por un conjunto de valores que definen la forma de onda, sino que dichas formas de onda se representan por ecuaciones algebraicas.
Adicionalmente, G.723.1 utiliza un sistema de supresión del silencio conocido como SID (Silence Insertion Description, ‘Descripción de la inserción de silencio’). Este sistema solo necesita transmitir 4 octetos, por lo que el silencio sólo ocupa 1 Kbps.
El inconveniente de los sistemas G.723.1 es el gran retardo total que genera (superior a 37,5 milisegundos), debido, entre otras cosas al tiempo necesario para llevar a cabo el análisis (7,5 milisegundos). Las calidades conseguidas con este codec de audio están en torno a los 3,8 MOS. No obstante, en enlaces que añadan retardos excesivos los niveles de calidad bajan tremendamente. A pesar de todo, este tipo de codificación resulta muy interesante en aplicaciones que disponen de muy poco ancho de banda.
G.729. CS-ACELP
Otras de las líneas de trabajo que se han seguido para reducir el ancho de banda necesario ha sido el sistema de codificación de la voz conocido como CS-ACELP (Conjugate Structure ACELP, ‘ACELP con estructura conjugada’). Con este sistema se consigue que el ancho de banda necesario sea de 8 Kbps. Para ello se toman 8.000 muestras por segundo y se identifican los parámetros de predicción y modelo del libro de códigos con cada grupo de 80 muestras. Al destino se envían tramas de 80 bits por cada grupo. El resultado es 8 Kbps (8.000×80/80).
CS-ACELP utiliza dos libros de códigos: uno fijo y otro adaptable. El primero de ellos contiene formas de onda preestablecidas, mientras que el segundo contiene formas de onda que se van adaptando a las señales que se van reconstruyendo. El resultado es una mayor calidad de voz. Para el cálculo de los parámetros de predicción no sólo se utiliza el grupo de 80 muestras (10 milisegundos), sino que también se tienen en cuenta las muestras de los 5 milisegundos siguientes. El retardo del algoritmo es 15 milisegundos.
El estándar G.729 de UIT-T se basa en este sistema. Posteriormente se publicarían distintas mejoras: G.729A (MOS 3,7), G.729B (que le saca mayor eficiencia a los periodos de silencio), G.729D (que trabaja a 6,4 Kbps con MOS 3,8) y G.729E (utiliza 11,8 Kbps pero ofrece una mayor calidad de voz).
Otros codificadores
Aparte de los codecs normalizados descritos anteriormente, en el mercado se han desarrollado otro tipo de codec de audio que han sido utilizados, fundamentalmente, para los sistemas de telefonía móvil digital. Este es el caso, por ejemplo, de los sistemas siguientes:
- CDMA QCELP (Qualcom CELP, IS-733). Se trata de un codificador de velocidad variable que se utiliza en los sistemas de telefonía móvil del tipo CDMA (IS-95). Aunque QCELP puede funcionar a distintas velocidades, las más comunes son 6,2 y 13,3 Kbps.
- GSM EFR (Enhanced FR, ‘FR mejorado’). Este sistema, utilizado como alternativa al original FR se basa en la técnica ACELP, trabaja a 12.200 bps (FR lo hacía a 13.000 bps) y ofrece una mejor calidad que FR.
- GSM AMR (Adaptative Multi-Rate, ‘Multivelocidad adaptable’). Se trata de un sistema que puede trabajar en 8 modos distintos con velocidades que van desde 4,75 a 12,2 Kbps. Cuando opera a 12,2 se trata del sistema EFR. El sistema puede cambiar de un modo a otro cada 20 milisegundos para adaptarse a las condiciones del entorno. El sistema AMR es utilizado para la telefonía móvil de tercera generación.
Más información sobre los codec de audio
Aquí se ha expuesto de forma resumida cómo funcionan los principales estándares de codecs de audio. Con suerte, habré sido capaz de generar dudas y crear curiosidad sobre este tema. En este blog se dispone de muchos otros contenidos relacionados. Por favor, utilice el buscador de contenidos que tenemos en la cabecera de este blog.
Estos son algunos otros artículos que pueden ser de interés:
- Cómo funciona la telefonía IP o VoIP.
- Técnicas de codificación de la voz
- VoIP. La telefonía de Internet
REF: VOIP PG50