
ChartGPT es un software de inteligencia artificial capaz de conversar con el usuario utilizando el lenguaje de forma similar a como lo hacemos los humanos. ChatGPT genera respuestas que son sorprendentemente coherentes y naturales. Los resultados son tan sorprendentes que está despertando un gran interés social sobre las herramientas de inteligencia artificial. En este artículo se describe cómo funciona ChatGPT por dentro. Cómo es posible que un software pueda escribir textos de una forma muy parecida a cómo lo hacen los humanos. Veamos qué sucede en el interior de ChatGPT para que todo esto sea posible.
Hay que aclarar que la tecnología que hace posible el funcionamiento de ChatGPT no es simple. No obstante, se explicará paso a paso cada una de las piezas que lo hacen funcionar. Se intentará hacer una descripción que sea comprensible por el público en general, sin entrar en profundidades. No obstante, el que tenga interés en profundizar en estos temas encontrará en este artículo un punto de partida a partir del cual seguir investigando y desarrollando cada uno de los apartados que conforman este campo tecnológico.
Hacer que una máquina pueda mantener una conversación con cierta coherencia resulta ser un problema mucho más simple de lo que se podría pensar
Como se podrá comprobar a continuación, la conclusión de todo esto es que escribir un ensayo, un texto, con un lenguaje similar al empleado por los humanos, resulta ser un problema mucho más simple de lo que se podría pensar. Siempre hemos pensado que escribir, hablar, es algo propio de humanos. Lo que veremos a continuación es que, ciertamente, los humanos somos especiales, pero hacer que una máquina pueda escribir o mantener una conversación con cierta coherencia, no es tan complicado.

Procesamiento del lenguaje natural o PLN
Al software que es capaz de conversar con un usuario utilizando el lenguaje de forma similar a como lo hacemos los humanos se le conoce como procesamiento de lenguaje natural o PLN (en inglés NPL o Natural Language Processing). El PLN es una rama de la inteligencia artificial que ayuda a los ordenadores a entender, interpretar y manipular el lenguaje humano.
Existen básicamente dos formas de abordar el procesamiento de lenguaje natural:
- Sistema lógico. Se basa en la creación de reglas y patrones predefinidos que permiten al sistema interpretar y producir lenguaje natural. Estas reglas se crean mediante la identificación de los patrones gramaticales y semánticos propios del lenguaje humano. Por ejemplo, una regla podría ser «el sujeto debe concordar con el verbo en número y género» o «un verbo transitivo debe tener un objeto directo». Un software de este tipo debe contener todas las reglas gramaticales en su interior y disponer de un motor lógico que permita estructurar su producción.
- Sistema probabilístico. Utiliza técnicas basadas en estadísticas y probabilidades para procesar el lenguaje natural. Estos modelos son entrenados con grandes volúmenes de datos para aprender las relaciones y patrones entre las palabras y frases en el lenguaje natural. Básicamente, se basa en estudiar la probabilidad de aparición de las siguientes palabras conforme se va creando la frase.
Los sistemas lógicos tienen grandes limitaciones debido a que el lenguaje humano resulta ser realmente complejo y ambiguo. Los algoritmos no son muy buenos para gestionar ambigüedades. Sin embargo, se están obteniendo resultados sorprendentes con los diversos modelos de lenguaje probabilístico que se están desarrollando en la actualidad.
Modelos de lenguaje natural probabilístico
Las estadísticas y probabilidades se pueden utilizar de formas muy distintas para construir un modelo de lenguaje natural. Distintas investigaciones han tomado caminos diferentes para lograr producir textos. El resultado es que se han creado varios modelos, cada uno con sus propias características y objetivos (clasificación de texto, análisis de sentimiento, traducción automática, etc.).
Explicar las características de cada modelo no es el objetivo de este contenido, por lo que nos limitaremos a mencionar los modelos de lenguaje natural probabilístico más conocidos, junto con una breve descripción. Aunque esta clasificación resulte poco clarificadora, el objetivo es aclarar que existen diversas formas de abordar el problema. Por favor, no se preocupe si le resulta confuso y siga leyendo.
Estos modelos son los siguientes:
- Modelos de lenguaje basados en n-gramas. Se basan en la frecuencia de aparición de secuencias de palabras (n-gramas) en el corpus de entrenamiento para predecir la siguiente palabra en una oración.
- Modelos de lenguaje basados en redes neuronales. Utilizan técnicas de redes neuronales para aprender las relaciones y patrones entre las palabras y frases en el lenguaje natural. Algunos ejemplos son las Redes Neuronales Recurrentes (RNN) y las Redes Neuronales Convolucionales (CNN).
- Modelos de lenguaje basados en modelos de Markov ocultos (HMM). Utilizan los modelos de Markov para modelar la probabilidad de una secuencia de palabras en función de las probabilidades de transición de estado de un HMM.
- Modelos de lenguaje basados en modelos de tema. Utilizan técnicas de aprendizaje no supervisado para identificar los temas latentes en el corpus de entrenamiento y luego utilizan estos temas para predecir la siguiente palabra en una oración.
- Modelos de lenguaje basados en Transformadores. Utilizan una arquitectura conocida como transformador para modelar las relaciones entre las palabras en una oración.
Modelo de lenguaje de gran tamaño o LLM
ChatGPT utiliza un tipo de modelo de lenguaje natural probabilístico conocido como modelo de lenguaje de gran tamaño o LLM (Large Language Model). Este modelo utiliza varias de las técnicas de los modelos probabilísticos mencionados anteriormente. Por ejemplo, utiliza las redes neuronales, los modelos de tema y los modelos basados en transformadores.
En cualquier caso, lo que hace que los LLM sean diferentes es su capacidad para procesar grandes cantidades de textos (de datos) y aprender de forma autónoma a partir de esos datos. Estos modelos son entrenados con enormes conjuntos de datos de lenguaje natural y utilizan técnicas de aprendizaje profundo (deep learning) para aprender las relaciones complejas entre las palabras y las frases.
ChatGPT es un modelo probabilístico desarrollado sobre un modelo de lenguaje natural de gran tamaño. Se basa en técnicas de aprendizaje profundo para poder ser entrenado con grandes volúmenes de datos.
Entrenar estos modelos consiste en fijar el valor de cada uno de sus parámetros. Para hacernos una idea de la complejidad de esta tarea, el modelo de lenguaje GPT-4 de OpenAI (que no es el más potente) utiliza entre 1 y 1,8 millones de millones de parámetros (1012, 1 billón europeo, no americano). GPT (Generative Pre-trained Transformer) utiliza la arquitectura transformer para modelar las relaciones entre las palabras en una oración. Por otro lado, es capaz de realizar una amplia variedad de tareas de procesamiento de lenguaje natural: generación de texto, traducción automática o responder preguntas. Todo esto sin necesidad de entrenamiento adicional para cada tarea específica.

Para entrenar el modelo se utilizan grandes volúmenes de datos (textos) procedentes de internet y de otras fuentes (básicamente, libros digitalizados). En internet hay varios miles de millones de páginas escritas por humanos y se han digitalizado más de 5 millones de libros, aparte de los textos derivados de los vídeos publicados. En total puede haber disponibles más de 100 mil millones de palabras de textos escritas por humanos para poder entrenar esta inteligencia artificial.
Cómo ChatGPT crea los textos
Hasta ahora nos hemos limitado a situar la solución tecnológica empleada por ChatGPT dentro del contexto general del procesamiento del lenguaje natural. Hasta aquí, lo que podemos suponer es que ChatGPT no es más que una gran máquina de análisis de probabilidades.
La capacidad de conversar de ChatGPT proviene de lo que aprende, de lo que registra y analiza durante su proceso de entrenamiento. El entrenamiento le permite predecir con precisión qué palabra viene a continuación en una oración. Esto es, ChatGPT está continuamente analizando y decidiendo cada palabra con la que continuar el texto de respuesta. Esta continuación razonable del texto se basa en lo que se podría esperar después de haber analizado miles de millones de textos.
Por ejemplo, si le preguntamos a ChatGPT: ‘¿Qué es lo que hace mejor una inteligencia artificial?‘, ChatGPT no realiza una análisis complejo de la pregunta, busca posibles respuestas y muestra la que le parece más apropiada. Nada de eso. Su forma de actuar es, aparentemente, mucho más simple. Sencillamente responderá: ‘Lo que hace mejor una inteligencia artificial es…‘. A partir de aquí, ChatGPT seguirá añadiendo palabras una a una. Gracias a su entrenamiento, ChatGPT toma estas palabras ya escritas y calcula la probabilidad de cada una de las palabras que pueden venir a continuación.
Si en el diccionario existen unas 50 mil palabras, en base a los millones de textos que ha analizado ChatGPT durante su entrenamiento, sabe la probabilidad que tiene cada una de estas palabras de estar escritas a continuación de cada una de las otras. Incluso la probabilidad de que vengan más de dos palabras juntas. Por ejemplo, en el texto del ejemplo anterior, es posible que las palabras con mayor probabilidad sean: aprender (4,5%), predecir (3,5%), realizar (3,2%), comprender (3,1%) o hacer (2,9%).

Dicho de otra manera, cuando ChatGPT escribe un texto, lo que está haciendo realmente es analizando una y otra vez cuál debería ser la siguiente palabra, teniendo en cuenta lo escrito hasta el momento.
Cuando ChatGPT escribe un texto, lo que realmente hace es analizar una y otra vez cuál debería ser la siguiente palabra, teniendo en cuenta lo escrito hasta el momento.
El efecto aleatorio
Con cada paso, obtiene una lista de palabras con probabilidades. Se podría pensar que siempre debe ir eligiendo la palabra con una mayor probabilidad. Si embargo, se ha comprobado que al hacer esto el resultado es un texto muy estándar, incluso donde se repiten palabras o frases frecuentemente. Para conseguir un texto más natural, más humano, es necesario incluir un cierto azar y no elegir siempre la palabra con mayor probabilidad.
El uso de este parámetro de aleatoriedad hace posible que, haciendo la misma pregunta dos veces seguidas, ChatGPT pueda producir respuestas distintas. ChatGPT llama temperatura a este parámetro de aleatoriedad. Después de realizar múltiples experimentos ha llegado a la conclusión práctica de que ajustando la temperatura a 0,8 es como se obtienen mejores resultados. No hay ninguna explicación para esto, salvo la pura experimentación.
Modelo de estimación de probabilidades
Lo cierto es que con unas 50 mil palabras de uso más o menos habitual, este sistema supondría que cada vez que se va a elegir una palabra para añadir al texto habría que hacer miles de millones de comparaciones. Esta solución es demasiado compleja como para resultar útil. Así que hay que buscar una forma de simplificarlo. La respuesta es hacer un modelo que nos permita estimar las probabilidades con las que deberían ocurrir las secuencias de palabras. ChatGPT ha construido un modelo para hacer este trabajo de estimación de probabilidades.
Para explicar el concepto de este modelo, supongamos que no conocemos las leyes físicas por las que se rige la gravedad. Queremos saber el tiempo que tarda un objeto en llegar al suelo al ser lanzado desde una determinada altura. Para averiguarlo, hacemos repetidos experimentos y anotamos los resultados en una tabla. A continuación, buscamos un modelo matemático que se adapte a estos resultados prácticos.
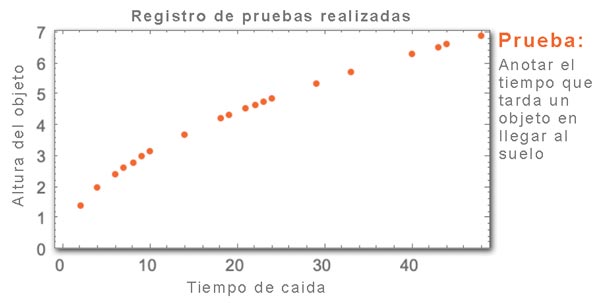
Por ejemplo, podemos empezar suponiendo que el modelo responde a una línea recta (función del tipo y = ax + b). Una vez que tenemos el modelo, solo hay que sustituir x por la altura deseada y encontraremos la respuesta y. Esta función simple nos da una respuesta aproximada correcta para muchas de las suposiciones, pero falla para muchas otras.
Lo intentamos con otro modelo. En este caso emplearemos una función del tipo y = a x 2 + b x + c. Vemos que los resultados obtenidos se ajustan mejor a lo deseado. Se podría seguir experimentado con otros muchos modelos o funciones más complejas y comprobar qué tal funcionan. Después de realizar múltiples experimentos nos quedamos con el modelo que nos ofrece mejores resultados. Recordemos que no conocemos las leyes físicas, por lo que se trata de una pura experimentación práctica.
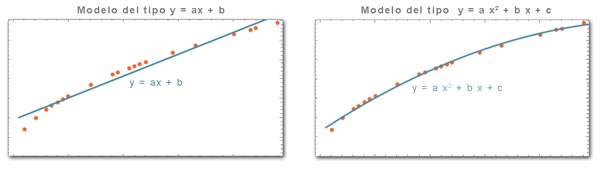
Hay que tener en cuenta que no solo se trata de elegir la función matemática que mejor se adapte al experimento, sino elegir también los parámetros que lo regulan. En este ejemplo tenemos una función y tres parámetros (a, b y c). ChatGPT utiliza un sistema similar. Por un lado, las funciones matemáticas están integradas en la red neuronal que utiliza. Por otro lado, utiliza miles de millones de parámetros que son ajustados durante el entrenamiento. Para que nos hagamos una idea, el motor de ChatGPT (GPT-3) utiliza 175 mil millones de parámetros y más de una función matemática.
El entrenamiento al que se somete la inteligencia artificial de ChatGPT es necesario para definir qué tipo de red neuronal utilizar, qué funciones y los valores de sus parámetros. Con todo esto definido, el modelo de ChatGPT es capaz de calcular bastante bien las probabilidades que tienen las siguiente palabras. No consulta una base de datos de probabilidades, sino que las calcula. El resultado es un texto razonable con la longitud deseada para el ensayo.
Redes neuronales artificiales
En los cerebros humanos hay unos 100 mil millones de neuronas interconectadas. A las neuronas llegan señales eléctricas, por ejemplo desde las células fotorreceptoras de la vista. Dependiendo de estas señales, cada neurona le pasa una determinada señal eléctrica a otras neuronas. Cada neurona tiene diferentes conexiones y contribuye con distinto peso. El resultado de este proceso es que reconocemos la imagen y formamos pensamientos.
En la década de 1940 se crearon pequeñas redes neuronales artificiales que pretendían simular el funcionamiento del cerebro natural. El concepto de redes neuronales artificiales ha evolucionado mucho desde entonces.
Una neurona es una elemento simple. Cada una recibe diversas señales de otras neuronas, realiza una cierta operación con estas entradas y genera una señal resultante que transmite. Podemos suponer que cada neurona aplica una función matemática a las señales de entrada para obtener la señal de salida. En las redes neuronales artificiales cada neurona es una función matemática. Por tanto, una red neuronal artificial es un conjunto de funciones matemáticas (neuronas) interconectadas. Por otro lado, cada función matemática necesita unos parámetros para que funcione correctamente.
Las neuronas se disponen generalmente formando capas. Hay neuronas que reciben datos del exterior, neuronas localizadas en capas intermedias (llamadas capas ocultas) y otras que muestran los resultados al exterior.
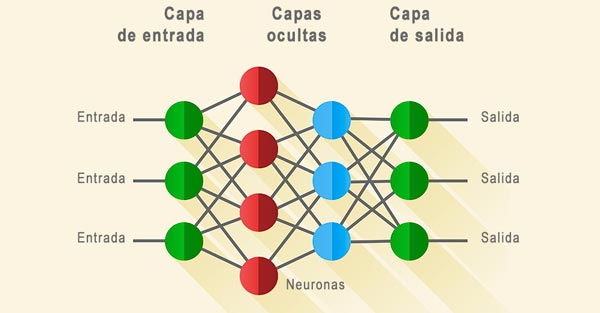
En la configuración tradicional de las redes neuronales artificiales, cada neurona tiene un cierto número de conexiones entrantes (x) que le vienen de las neuronas de la capa anterior. Al valor de cada conexión entrante se le aplica un cierto peso (w), una cierta ponderación. Por otro lado, cada neurona tiene configurado su propio parámetro (b). También tenemos que la neurona aplica una función matemática con estos valores para obtener el valor de salida, y = f(w·xn+b).
Una red neuronal artificial es un conjunto de funciones matemáticas (neuronas) interconectadas. El tipo de función a utilizar se determina con la experimentación y el valor de sus parámetros mediante el entrenamiento.
Los pesos w y constante b generalmente se eligen de manera diferente para cada neurona en la red, mientras que la función f (conocida como función de activación) suele ser la misma para todas ellas (aunque no necesariamente).
Aunque no vamos a entrar a explicar el por qué, el hecho es que existen diferentes tipos de funciones de activación. La determinación del tipo de función a utilizar, así como la configuración de la red neuronal y el valor de los distintos pesos se fijan con la experimentación y durante el entrenamiento del modelo. Una vez definido todo esto, lo cierto es que el resultado matemático de la red neuronal podría escribirse en forma de una única función matemática general: y = w51·f(w31·f(b1+x·w11+y·w12)+….

La red neuronal de ChatGPT también corresponde a una función matemática como esta, pero con miles de millones de términos.
Entrenamiento de redes neuronales
Como hemos visto, los parámetros que utilizan las redes neuronales se fijan gracias al entrenamiento. Por ejemplo, si se necesita que una red neuronal nos diga si hay un gato en una foto, no será necesario escribir un algoritmo que explícitamente busque unas orejas puntiagudas o unos bigotes. En vez de eso, tendremos que proporcionarle múltiples ejemplos de fotos e indicarle si hay o no un gato en cada una de ellas. Después del entrenamiento, la red habrá adaptado sus parámetros para encontrar la forma de hacer esta discriminación. En realidad, la red neuronal actúa como una caja negra. Como utiliza millones de parámetros, una vez entrenada, no sabemos exactamente cómo influye cada uno de los parámetros. Lo que sí sabemos es que, si le introducimos una foto, nos determinará si en ella aparece o no la imagen de un gato.
El entrenamiento de la red neuronal es lo que se conoce como aprendizaje automático (machine learning) o aprendizaje profundo (deep learning). En el primer caso el entrenamiento se produce con intervención humana y en el segundo se trata de un aprendizaje completamente autónomo.
Lo que se hace durante el proceso de entrenamiento es buscar los pesos que hacen que la red neuronal reproduzca el resultado deseado. El software de entrenamiento va jugando con el valor de cada uno de estos pesos hasta dejarlos ajustados. Posteriormente, solo cabe esperar que la red aplique estos pesos para ofrecer resultados razonables. Como se puede ver, se trata de un uso reiterado de probabilidades. La salida de las redes neuronales son el resultado de aplicar las estadísticas una y otra vez. Aunque esta técnica tiene sus fallos, el resultado general es de una calidad bastante razonable.
En el ejemplo del gato, no se trata de que literalmente la red reconozca el patrón de píxeles de la imagen de un gato. Lo que hace la red neuronal con los píxeles es someterlos a un análisis estadístico en base a los pesos determinados durante el entrenamiento y concluir si es o no un gato.
Cómo se ajustan los parámetros de las redes neuronales
Pongamos otro tipo de ejemplo. Supongamos que tenemos una determinada red neuronal con una entrada y una salida y tenemos como objetivo obtener una determinada función. Esto es, que para cada valor de x, la red responda con el valor de y correspondiente a esta función:
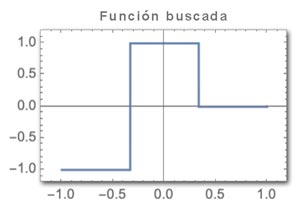
Si aplicáramos un conjunto de pesos al azar, obtendríamos salidas aleatorias que nada tienen que ver con lo que buscamos.
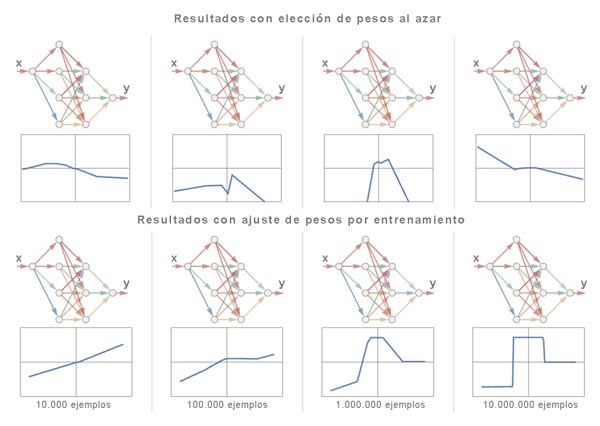
Sin embargo, si sometemos el modelo a muchos ejemplos de entrada y salida correctos, poco a poco irá ajustando los pesos para generar resultados cada vez mejores. Esto es, se le introduce pareja de valores x e y que representen la función correctamente. Con un número de ejemplos suficientemente grande, el resultado puede ser casi perfecto.
Como podemos ver en la imagen, los pesos de la red se van ajustando progresivamente hasta obtener un modelo que reproduce con éxito la función deseada. La técnica para ir ajustando estos pesos no es simple, pero mediante una metodología matemática puede irse ajustando las diferencias entre lo obtenido y lo deseado.
Por cierto, cabe señalar que no hay una única combinación de pesos que ofrezcan resultados correctos. En realidad, se encontrarán muchas colecciones diferentes de pesos que ofrecen prácticamente el mismo rendimiento. De hecho, durante el proceso de entrenamiento se toman muchas decisiones aleatorias, lo que hace que dos entrenamientos con los mismos datos puedan llevar a soluciones diferentes, aunque igualmente efectivas.
Aunque cada solución encontrada ofrezca soluciones equivalentes dentro del rango de valores que se le ha proporcionado durante el entrenamiento, lo cierto es que son soluciones diferentes. Las diferencias se manifiestan cuando se les pide respuesta para un rango de valores más amplio.
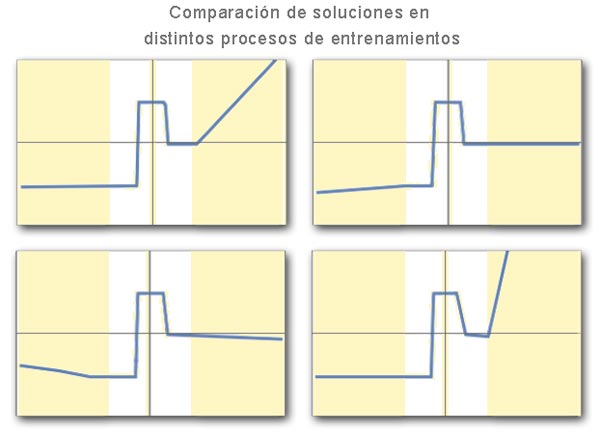
Por tanto, todas las soluciones son distintas pero correctas. Si se desea mejorar el resultado habrá que proporcionarle un rango de valores de entrenamiento mayor. De ahí que cuanto más datos de entrenamiento se le proporcione al modelo, más calidad tendrán los resultados obtenidos.
En definitiva, la idea fundamental de las redes neuronales es crear una estructura flexible a partir de un gran número de componentes simples (esencialmente idénticos). A partir de aquí, hacer que esa estructura pueda modificarse gradualmente para aprender de los ejemplos. Las redes neuronales están configuradas para tener una estructura con un número fijo de neuronas. Lo que se modifica en el entrenamiento es el peso de las conexiones entre ellas.
Representar el texto con números
La informática en general y las redes neuronales en particular se basan fundamentalmente en el uso de números, de ceros y unos. Para estos sistemas, un texto o una letra no significan nada, no son comprensibles. Por tanto, hay que encontrar una forma de convertir textos en números. En un principio, lo que hace ChatGPT para resolver este problema es identificar cada palabra del diccionario con un número.
No obstante, ChatGPT va más allá de esto. No realiza una asignación de números de forma alfabética o al azar, sino que ha buscado que las palabras con significados cercanos sean representadas con números cercanos. Es como si tuviéramos un tablero en blanco de significados y se van insertando, incrustando, cada palabra en el lugar que le corresponde de acuerdo a lo que representan. Se trata de asignar números por acoplamiento de significados (embeddings). Cada palabra la va acoplando, insertando, en el lugar espacial que le corresponde de acuerdo a su significado. ChatGPT ha desarrollado un sistema complejo para hacer esto pero, si lo reducimos a un tablero de dos dimensiones, podría ser algo similar a lo siguiente:

Es más, ChatGPT no se limita a asignar números a cada palabra, sino que también asigna números a secuencias de palabras o, incluso, a textos enteros. Esto es, ChatGPT ha desarrollado un sistema que permite representar un texto de forma numérica. A este número lo llama vector de incrustación. Esto hace que, dado un texto, encontrar las probabilidades de las diferentes palabras que pueden venir a continuación, se convierta en una tarea más asumible.
ChatGPT le asigna un número a cada palabra buscando que las palabras con significados cercanos sean representadas con números cercanos. Este número se conoce como vector de incrustación.
Una puntualización importante: ChatGPT no utiliza solo palabras para crear sus ensayos. Para poder crear todo tipo de textos utiliza unidades lingüísticas a las que llama tokens. Un token pueden ser palabras completas pero también pueden ser prefijos, sufijos o terminaciones. Por ejemplo, ‘pre’, ‘post’ o las terminaciones de los gerundios ‘ando’, ‘endo’, etc.
Red neuronal transformador
ChatGPT utiliza un tipo de red neuronal conocida como transformador. Estas redes utilizan la idea de que determinadas partes del texto requieren más atención que otras. A este concepto lo llaman atención. Esto es, a la hora de decidir las probabilidades de la siguiente palabra a escribir, se tiene en cuenta, no solo las palabras precedentes, sino también las palabras significativas (con alta atención) que pudieran estar situadas bastante más atrás en el texto. Por ejemplo, esto permite añadir correctamente un verbo que se refiere a un sustantivo que aparece muchas palabras antes en el texto.
Para implementar esta idea, en la red neuronal de ChatGPT se hace pasar el texto por un bloque de atención que crea un nuevo vector de incrustación. De hecho, GPT-2 utiliza 12 bloques de atención. Cada uno de ellos tiene su propio patrón particular de pesos. El texto pasa sucesivamente a través de cada bloque de atención para obtener el vector de incrustación definitivo. La versión siguiente, GPT-3, tiene 96 bloques de atención.
Esencialmente, lo que se hace es transformar la colección inicial de incrustaciones que le correspondía a una secuencia de palabras y generar una nueva incrustación sobre la que buscar las probabilidades de la siguiente palabra a añadir al texto.
En resumen, cómo funciona ChatGPT por dentro
Como se ha visto a lo largo de este artículo, ChatGPT es una red neuronal inmensa (la versión GPT-3 utiliza 175 mil millones de pesos, neuronas) que ha sido entrenada con miles de millones de textos de la web y de libros digitalizados. ChatGPT conoce las similitudes de significado de las palabras (y grupos de palabras) y cómo están relacionadas entre ellas. Sabe qué probabilidades hay de que una palabra vaya a continuación de otra dependiendo del contexto. Su trabajo es continuar un texto de una manera razonable.
Por ejemplo, a la pregunta ¿Qué es la inteligencia artificial?. La respuesta sería ‘La inteligencia artificial es …‘ (o cabecera similar) y debería poder continuar este texto de acuerdo a su entrenamiento.
Como hemos visto anteriormente, ChatGPT toma la secuencia de palabras del texto de que dispone, encuentra el vector de incrustación que lo representa (una matriz de números). Toma la última parte de la matriz y estima las probabilidades que tiene cada palabra de estar colocada a continuación. Por último, elige una de las opciones con mayor probabilidad.

Como se puede ver, no hay una lógica de lenguaje natural programada en ningún algoritmo. Todo se hace en base a un comportamiento aprendido durante la fase de entrenamiento. En realidad, no se conocen muy bien los detalles de lo que ocurre en el interior de este chat de IA durante la creación del texto. La única manera de controlar la calidad de su producción es mediante el entrenamiento. Si no deseamos que la IA utilice palabras malsonantes, no hay que introducirlas en el entrenamiento.
No hay una lógica de lenguaje natural programada en ningún algoritmo, sino que todo se hace en base a un comportamiento aprendido durante la fase de entrenamiento.
El motor, el software que hace posible todo esto es un conjunto de neuronas artificiales interconectadas (de algoritmos). Cada interconexión está ponderada con un determinado peso. Cada algoritmo realiza un operación matemática simple. Por tanto, ChapGPT toma un texto que convierte en una matriz de números (un vector de incrustación) y lo va pasando por cada una de las capas de la red neuronal. Cada neurona hace su trabajo y le pasa el resultado a las neuronas de la capa siguiente. No hay retrocesos, cada neurona se utiliza solo una vez. El resultado es un número, un token, que representa la siguiente palabra a añadir al texto. Este trabajo se repite una y otra vez hasta concluir la respuesta.
La versión de ChatGPT basada en GPT 3 tenía alrededor de 400 capas de neuronas con un total de 175 mil millones de conexiones. Cada nueva palabra, cada nuevo token, supone involucrar a todas estas neuronas con todos sus cálculos implicados. Lo curioso es que cada neurona realiza una operación matemática simple, sin embargo, operando de forma conjunta, puede lograr crear textos realmente sorprendentes.
Lo que hace ChatGPT al generar un texto es realmente impresionante. Además, los resultados suelen ser muy parecidos a lo que produciríamos los humanos. No obstante, esto no significa que ChatGPT funcione como un cerebro. Su estructura de red neuronal artificial se modeló para copiar la estructura del lenguaje humano aprendida de los millones de textos de entrenamiento. Es simplemente una máquina que habla gracias a que el lenguaje humano no parece ser tan complicado como pensábamos en un principio. Esto no quita para que muchos de los aspectos que utiliza ChatGPT sean bastante similares a como lo hacemos los humanos para generar el lenguaje.
Muchos de los aspectos que utiliza ChatGPT son bastante similares a lo que hacemos los humanos para generar el lenguaje
Más información relacionada con ChatGPT
La inteligencia artificial en general y ChatGPT en particular son temas realmente interesantes sobre los que se pueden escribir una amplia diversidad de contenidos. En este artículo se ha intentado explicar de la forma más simple posible, cómo funciona ChatGPT por dentro. El objetivo no ha sido abordar este tema en profundidad, sino dar una idea cómo los ordenadores pueden mantener una conversación con los humanos de una forma natural. Esta tecnología no ha hecho más que empezar y ya está ofreciendo resultados asombrosos.
En este blog se aborda este tema desde otros puntos de vista, así como otros muchos temas relacionados. Si busca inspiración o simplemente le interesa la tecnología, por favor, utilice el buscador de contenidos que tenemos en la cabecera.
En cualquier caso, estos son algunos otros artículos que pueden ser de interés:
Buen artículo. Muchas gracias.
¿Dónde puedo encontrar información aún más profunda del funcionamiento de ChatGPT?
Un saludo
Muchas gracias Juan por al comentario. Si tienes alguna duda concreta, le puedes preguntar a ChatGPT. En cualquier caso, en el mercado existe una gran variedad de libros sobre el tema. Últimamente están saliendo muchas publicaciones nuevas que seguro que son mejores que las que yo utilicé. Esto va tan rápido que no me da tiempo a revisar la bibliografía. Pero, para no dejar la pregunta sin contestar, sin garantía de que sean los mejores, te incluyo alguno: (1) How Does ChatGPT Work? de Daniel D. (2) AI Made Simple: A Beginner’s Guide to Generative Intelligence de Rajeev Kapur o, uno en español, (3) CHATGPT: La Guía Más Completa de Manuel Moreno.
Muchas gracias. Me has resumido muchas dudas.
Muchas gracias por comentarlo. Un saludo.