
Como se ha visto, las técnicas de calidad de servicio se basan, fundamentalmente, en adaptar el funcionamiento de los nodos (routers) que forman parte de la red. Para lograrlo, no sólo se disponen de técnicas específicas, como RSVP o la diferenciación de servicios, sino que se cuenta con todo un conjunto de herramientas (protocolos, políticas o dispositivos) encaminadas tanto a la clasificación, tratamiento del flujo de tráfico y asignación de recursos, como a hacer que la red, en su conjunto, funcione eficazmente. En este artículo vamos a describir de forma genérica estas herramientas para la calidad de servicio en VoIP.
Para entender los conceptos explicados en este artículo, es necesario que previamente se hayan entendido estos otros:
- Cómo funciona la telefonía IP o VoIP
- VoIP. Necesidad de la calidad de servicio en Internet
- Protocolo RSVP de reserva de recursos
Básicamente, estos artículos vienen a describir que la transmisión de voz y vídeo por Internet necesitan unas reglas de enrutamiento distintas a la transmisión de datos de otro tipo de servicios (web, correo electrónico, etc.). Para solucionarlo, se han definido unos procedimientos conocidos como calidad de servicio, QoS. Estos procedimientos priorizan el tráfico de voz y vídeo frente a los otros tipos de tráfico. RSVP es el protocolo QoS más utilizado para la reserva de recursos.
Además de utilizar el protocolo RSVP, los nodos de la red necesitan aplicar otra serie de mecanismos que garanticen que se resuelve el enrutamiento del tráfico bajo cualquier circunstancia. Esto es a lo que se conoce como herramientas para la calidad de servicio.
Categorías de las herramientas
Como hemos visto, las herramientas para la calidad de servicio en VoIP son una serie de mecanismos creados para garantizar que se resuelve el enrutamiento del tráfico bajo cualquier circunstancia. En general, las herramientas existentes se pueden clasificar en las siguientes categorías:
- Clasificación de paquetes (packet classification). Esta técnica consiste en clasificar los paquetes que van entrando en la red para tratarlos de forma distinta según su contenido. Esta clasificación se puede llevar a cabo analizando, tanto el campo DS, como otros campos de la cabecera IP (tipo de protocolo, direcciones IP y puertos), lo que permite asociar cada paquete a un tipo de tráfico distinto. Una vez hecha la clasificación es posible aplicar un tratamiento distinto en cuanto a priorización y asignación de recursos.
- Utilización de colas (queue). Consiste en crear distintas colas de tráfico, a las que se les asigna un nivel de prioridad distinto. La cola de alta prioridad podría enrutar el tráfico sin demora, mientras que la de baja prioridad lo haría cuando hubiera recursos disponibles. Es importante que el tráfico de una cola no bloquee completamente el tráfico de las otras. Por este motivo, existen distintos modelos de gestión de colas: desde el modelo simple de estricta priorización descrito anteriormente, hasta el que asigna distintos recursos a cada cola, pasando por otros más dinámicos. La asignación de los paquetes a cada tipo de cola se haría con técnicas de clasificación de paquetes.
- Control de admisión (admission control). Esta técnica consiste en admitir en cada clase sólo el tráfico al que se le puede garantizar la calidad de servicio prometida. El resto del tráfico se rechaza. Es algo así como si un avión sólo tiene ocho asientos en primera clase, si una novena persona solicita esta clase se le tiene que informar de que no hay plazas disponibles y que puede optar por una clase inferior o por viajar en otro momento.
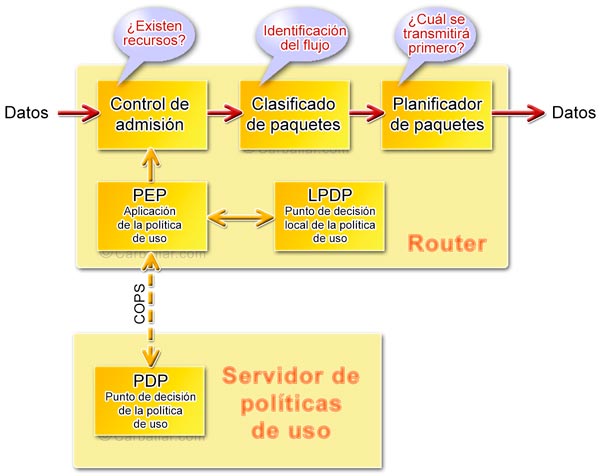
- Control de la política de uso (policy control). A los elementos de red (tales como routers y switches) se les puede configurar para que sigan unas determinadas reglas basadas en criterios como la identidad del usuario, tipo de aplicación, ancho de banda, etc. Estas reglas pueden configurarse localmente en cada dispositivo o pueden residir en un servidor externo de política de uso. Estos servidores externos reciben el nombre de PDP (Policy Decision Points, ‘Puntos de decisión de la política de uso’). Las reglas configuradas en los PDP suelen tener prioridad sobre las reglas configuradas localmente. A los elementos de red que aplican estas reglas se los conoce como PEP (Policy Enforcement Points, ‘Puntos de aplicación de la política de uso’). El control de las políticas de utilización de los dispositivos de red son una parte fundamental de la calidad de servicio.
- Aplicación de la política de uso (Policy Enforcement). Los dispositivos de red deben contar con las herramientas necesarias que les permitan controlar, aplicar y hacer un seguimiento de la utilización de sus recursos con respecto a las políticas de uso que tengan configuradas.
Política de uso de los recursos
Una vez que se cuenta con mecanismos que permiten aplicar distinta QoS a distintos tipos de tráfico, el siguiente paso sería definir la calidad de servicio a aplicar a cada tipo de tráfico. De este asunto se ocupa lo que se ha venido a llamar la política de calidad de servicio. Estas políticas especifican cómo se utilizan los mecanismos de diferenciación de tráfico y cómo se asignan los recursos.
Este punto es importante porque, no sólo se pueden aplicar distintos tratamientos a los distintos tipos de tráfico, sino que esta diferenciación también podría ser aplicable a distintos usuarios o a los distintos niveles de servicios contratados por los usuarios. Por ejemplo, podría haber usuarios de pago, que reciben una cierta QoS, mientras que el resto recibiría una QoS inferior. En ambos casos se trataría de transmisión de voz, pero el tratamiento sería distinto.
El IETF ha definido un protocolo conocido como COPS (Common Open Policy Service, ‘Servicios comunes de políticas de uso abiertas’), especificado en la RFC2748, que se encarga de la administración, configuración y aplicación de las políticas de uso de la red.
COPS es un protocolo cliente-servidor que se compone de los siguientes elementos:
- PEP (Policy Enforcement Point, ‘Punto de aplicación de la política de uso’). Se trata de los dispositivos que aplican las reglas (clientes COPS). COPS considera la posibilidad de definir distintos tipos de clientes.
- PDP (Policy Decision Point, ‘Punto de decisión de la política de uso’). Se trata del servidor donde están configuradas las políticas de uso para todos los tipos de tráfico y de servicios (servidor COPS).
Cuando un PEP necesita aplicar cualquier regla se lo pregunta a un PDP para que tome la decisión oportuna. Mientras que el PEP viene a ser como la policía, el PDP hace el papel de juez.
Gracias a COPS se puede disponer de un modelo donde las políticas de uso se definen de forma centralizada. Los elementos PEP de la red, simplemente consultan los servidores PDP antes de tomar cualquier decisión. El protocolo COPS utiliza TCP como protocolo de transporte para asegurar la fiabilidad del intercambio de mensajes.
En el modelo COPS se contempla la posibilidad de que el cliente COPS disponga de una cierta autonomía de toma de decisión. La unidad local de toma de decisión se conoce como LPDP (Local Policy Decision Point, ‘Punto de decisión local de la política de uso’).
Control de la congestión
La congestión es la situación que se produce cuando se llenan las colas de un nodo, no pudiéndose almacenar los nuevos paquetes que llegan. En estas situaciones, los nuevos paquetes entrantes se desechan directamente, teniendo que ser las aplicaciones quienes detecten estas pérdidas y retransmitan los paquetes (si es el caso). El inconveniente de estas situaciones es tanto la pérdida de paquetes (UDP) como el retardo que supone su retransmisión (TCP), lo que conlleva una pérdida de calidad.
Para evitar en lo posible las situaciones de congestión se utilizan distintas técnicas de encolado y planificación. Esto supone disponer, en los nodos, de memorias intermedias (búfer) que guardan temporalmente los paquetes hasta que pueden ser retransmitidos, así como una lógica de priorización y retransmisión de los paquetes.
Entre las principales técnicas de encolado se encuentran las siguientes:
- FIFO (First In, First Out, ‘El primero en entrar es el primero en salir’). En este caso, los paquetes se van retransmitiendo en el mismo orden en el que van llegando, sin distinciones. Por tanto, todos los paquetes que lleguen estando la cola saturada se desechan. Este es el esquema por defecto de casi todos los routers.
- PQ (Priority Queuing, ‘Encolado con prioridad’). En este caso, los paquetes se marcan con distintas prioridades y se van almacenando en colas distintas, de forma que las colas con mayor prioridad se vacían más rápidamente que las que tienen una prioridad menor. El problema que tiene este sistema es que si existe mucho tráfico de alta prioridad nunca se transmite el tráfico de prioridad baja. A este fenómeno se le conoce como traffic starvation (hambre de tráfico).
- CQ (Custom Queuing, ‘Encolado a medida’). En este caso también se crean colas con distintas prioridades, pero se define para cada una de ellas un número de paquetes mínimo para su retransmisión. De esta forma se garantiza un ancho de banda mínimo para cada cola.
- WRR (Weighted Round Robin, ‘Asignación cíclica ponderada’). En este caso se le asigna un peso a cada cola y se reparte el ancho de banda disponible en función del peso de cada una. A este sistema también se lo conoce como CBQ (Class Based Queuing, ‘Encolado basado en clases’).
Pongámonos ahora en el caso de que le llega un paquete de 1500 bytes a un router y que se encuentra la cola vacía. El router comenzará su retransmisión sin demora, pero, en ese preciso momento, llega un paquete de alta prioridad. Como el paquete anterior ya empezó a ser retransmitido, hay que esperar a que termine, lo cual implica añadir un retardo considerable en la retransmisión del paquete de alta prioridad. Para evitar esta circunstancia se creó la técnica LFI (Link Fragment and Interleaving, ‘Fragmentación e inserción’). Esta técnica consiste en trocear los paquetes en bloques de 10 milisegundos. De esta forma se limita el retardo máximo que puede sufrir un paquete en un nodo.
Claro que, si saber manejar la congestión cuando se produce es importante, también lo es poder evitarla (en lo posible). Pongámonos en otra circunstancia: cuando se congestiona un router se cortan muchas conexiones TCP de forma simultánea, lo que hace que se reduzca el caudal de forma abrupta. Esta reducción hace que desaparezca la congestión, pero, al comprobar las conexiones que hay caudal disponible, incrementan el tráfico, volviéndose a la situación de congestión. Para evitar este fenómeno oscilante existen mecanismos como RED (Random Early Detection, ‘Detección temprana aleatoria’), WRED (Weighted RED, ‘RED ponderada’) o DWRED (Distributed Weighted RED, ‘RED ponderada y distribuida’) que evitan la congestión de la red descartando paquetes de forma inteligente antes de alcanzar la situación de congestión.
MPLS
La tecnología MPLS es otra de las herramientas para la calidad de servicio en VoIP. Cuando un paquete llega a un nodo, lo primero que se hace es analizar su cabecera para determinar hacia dónde se tiene que enrutar, cuál será el siguiente salto. El nodo tiene que disponer de unos ciertos recursos para realizar este análisis (capacidad de proceso, memorias, etc.), que no son nada despreciables. Para resolver este problema, la IETF publicó en enero de 2001 la recomendación RFC3031 que describía el protocolo conocido como MPLS (Multiprotocol Label Switching, ‘Conmutación de etiquetas multiprotocolo’).
MPLS le asigna una etiqueta a cada paquete que entra en la red. Esta etiqueta contiene toda la información necesaria para el encaminamiento. De esta forma, los nodos no tienen que leer toda la cabecera de cada uno de los paquetes, basta con que miren la etiqueta. La gran ventaja de MPLS es que consigue decisiones de enrutamiento más rápidas, lográndose, de esta forma, mejorar la QoS.
Los nodos que admiten el protocolo MPLS reciben el nombre de LSR (Label Switched Router, ‘Router de conmutación de etiquetas’). Al conjunto de LSR interconectados se lo conoce como dominio MPLS. Los nodos periféricos de este dominio se conocen como LER (Label Edge Router, ‘Router periférico de etiquetas’). Estos nodos son los que asignan las etiquetas a los paquetes entrantes en el dominio y las retiran en el momento de salir del mismo. A la hora de asignar la etiqueta se decide la ruta que va a seguir el paquete dentro del dominio MPLS. Para ello, se emplea la técnica de encaminamiento CBR (Constrained Based Routing, ‘Enrutado basado en restricciones’) que consiste en calcular las rutas óptimas en función de las condiciones del contorno.
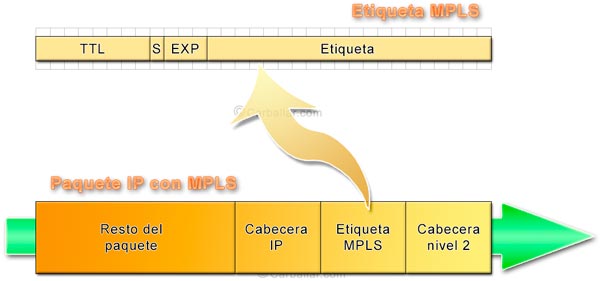
Las etiquetas MPLS se adjuntan en el paquete delante de la cabecera IP y lo identifican como perteneciente a una clase FEC (Forwarding Equivalence Class, ‘Clase de paquetes equivalentes para el reenvío’). Todos los paquetes que pertenecen a una misma clase son tratados de la misma forma desde el punto de vista del enrutamiento. Por tanto, todos los paquetes de un mismo flujo de datos tendrán el mismo FEC y seguirán exactamente la misma ruta hasta llegar a su destino, llegando en el mismo orden en que son transmitidos. Al camino que siguen los paquetes por el dominio MPLS se lo conoce como LSP (Label Switched Path, ‘Ruta de los paquetes conmutados por etiquetas’).
Con MPLS se puede asegurar también que a cada sesión se le asignarán los recursos que necesita. A esta técnica, con la que se puede asignar a un tipo específico de tráfico una ruta específica y los recursos de red necesarios se la conoce como ingeniería de tráfico (traffic engineering, RFC2702).
Más información sobre herramientas para la calidad de servicio en VoIP
- Protocolo RSVP de reserva de recursos
- Formato de los mensajes RSVP
- RTP. Protocolo de transporte en tiempo real
REF: VOIP PG216